在图像相似度比较的过程中,笔者意外发现可以利用CLIP快速搭建一个私有的图像搜索系统。本文将详细介绍图像搜索的关键实现步骤,并深入探讨背后的原理,包括向量相似度与检索优化、向量数据库、Transformer架构以及CLIP的源代码实现等。
[TOC]
一 本文实现了什么
CLIP (Contrastive Language–Image Pre-training) 是 OpenAI 开发的图文多模态模型 ,它利用从互联网抓取到的图像-文字pair数据进行训练,使用对比学习的方式来学习图像和文本之间的语义对应关系。
笔者借助CLIP模型,实现了一个简单的图像搜索系统。这是演示示例,包括以文搜图&以图搜图:
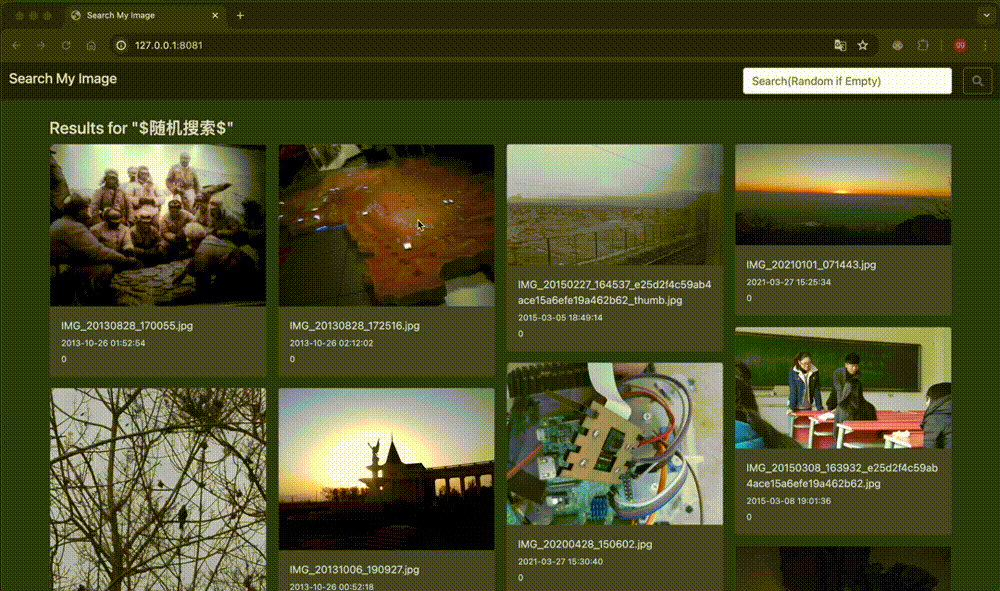
本文介绍了图像搜索的关键实现。并额外探究、记录了背后的一些原理,包括包括向量相似度与检索优化、向量数据库、Transformer和CLIP源代码实现。。
二 背景
1 从图像相似度比较说起…
在视觉稿转代码项目中,不可或缺是建立一套标准,通过比较原视觉稿与所生成代码视觉之间的差异,来确定还原效果。这里有一套简单、快速的像素级图像比较方案:pixelmatch。pixelmatch 只有约150 行代码,没有依赖关系,并且适用于原始类型的图像数据数组。
| Diff | expected | Actual |
|---|---|---|
 |  |  |
 |  |  |
但在 pixelmatch 的使用过程中,发现其对于背景是不敏感的。比如下面这个示例,pixelmatch对比两个图片的相似度,高达0.91。
而在Design2Code: How Far Are We From Automating Front-End Engineering?这篇论文中介绍到,他们使用CLIP来判别两张图片在宏观上的差异性。
High-level Visual Similarity To evaluate the visual similarity of ImageR and ImageG, we use the similarity of their CLIP embedding, denoted as CLIP(ImageR, ImageG). Specifically, we extract features by CLIP-ViT-B/32 after resizing screenshots to squares. To rule out the texts in the screenshots, we use the inpainting algorithm from Telea to mask all detected text boxes using their bounding box coordinates.
参考使用clip后,相似度就符合直观预期地比较低了:
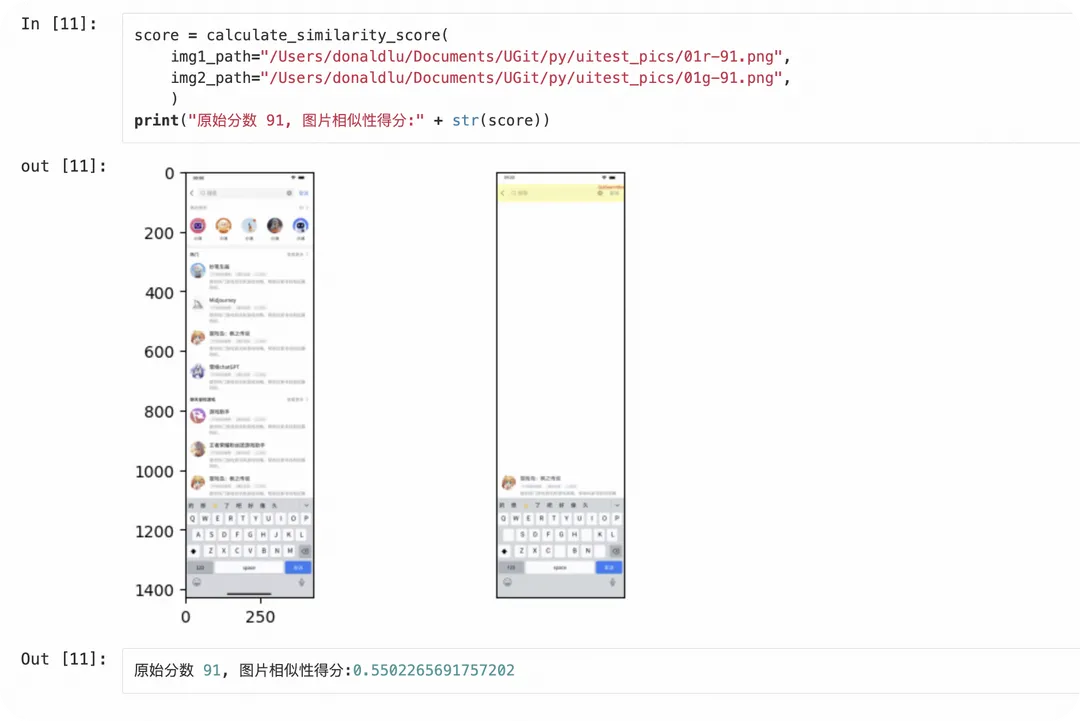
不可思议的是,使用CLIP时,笔者的calculate_similarity_score的代码量太少了,核心代码只有十多行。这引发了笔者的好奇,并想探究一下其背后的原理。
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
def calculate_similarity_score(img1_path, img2_path):
image1_data = preprocess(Image.open(img1_path)).unsqueeze(0).to(device)
image2_data = preprocess(Image.open(img2_path)).unsqueeze(0).to(device)
# Calculate the embeddings for the images using the CLIP model
with torch.no_grad():
image1_embedding = model.encode_image(image1_data)
image2_embedding = model.encode_image(image2_data)
# Calculate the cosine similarity between the embeddings
similarity_score = torch.nn.functional.cosine_similarity(image1_embedding, image2_embedding)
return similarity_score.item()
2 岂不是可以快速构建图片搜索引擎?
举例来说,比如我们的手机相册、或聊天记录里,有这样的几张瓷器图片。

经过笔者的尝试,发现 华为相册、小米相册、QQ消息记录、微信消息记录 其实都是搜不到这些瓷器图片的:
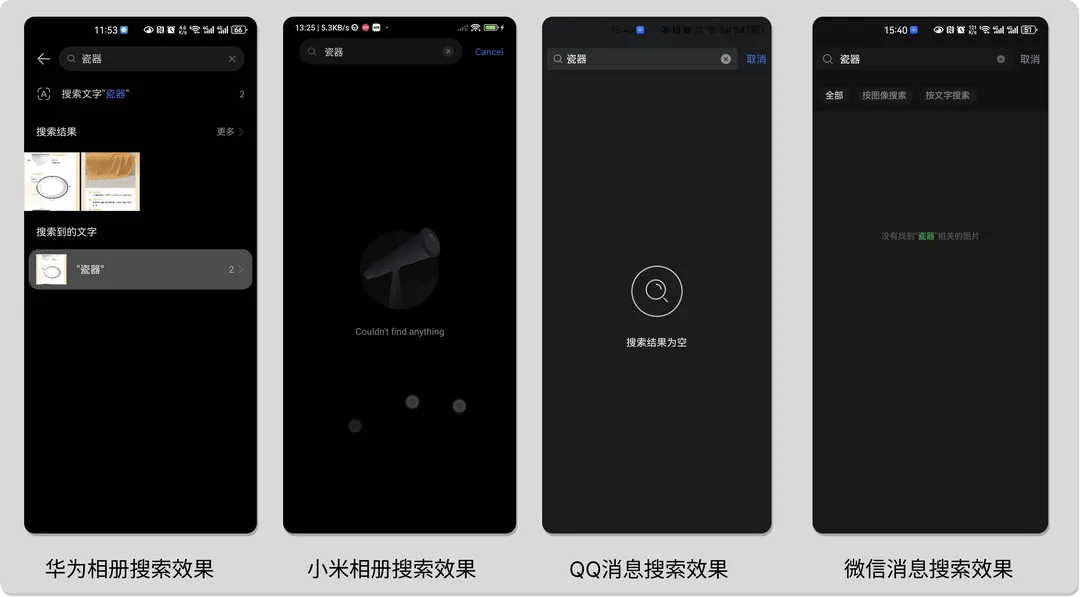
既然clip能够做图像的相似度比较,岂不是可以用来轻易实现图像语义搜索?简单地尝试之后,笔者就用clip实现了个简单的demo,搜索“瓷器”的演示示例如下:
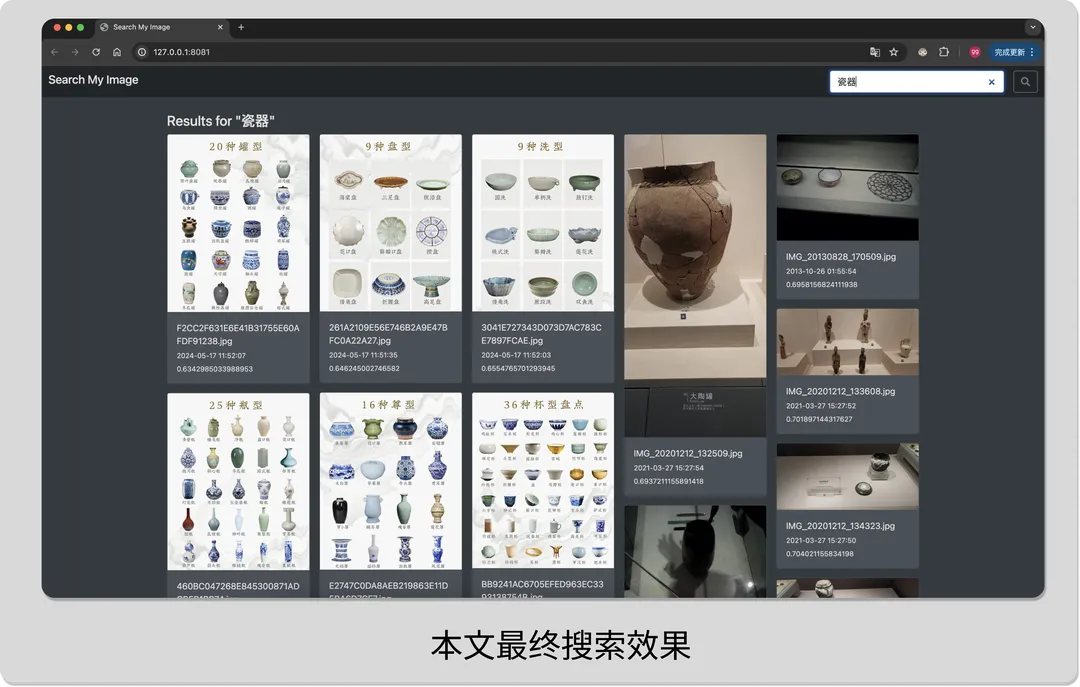
三 代码实现
笔者主要借助clip+Chroma+sqlite3+flask实现。
1 clip
这一步的代码实现比较简单,主要是借助CLIP相关模型,将指定目录下的图像文件,批量一一转为向量数据。
值得一提的是,这里最好不要直接使用OpenAI 开源的 CLIP 模型。因为 OpenAI CLIP训练用的图文数据是英语世界中的图像,这和中文世界中的图像有很大的数据分布差异,涉及到一些譬如成语、生活习俗、城市地点时可能会出现偏差较大的情况。
这里笔者使用的是一个中文 CLIP 模型。社区中有不少针对中文场景训练的 CLIP 模型可供选择,使用起来也比较简单,如下即可分别将图像、文本数据转为向量数据。
import weclip
import torch
# usage: my_clip_model = MyClipModel('checkpoints/weclip_base.pth')
class MyClipModel:
def __init__(self, clip_model_name):
# 初始化模型
self.model = weclip.WeCLIPBase()
self.model.load_state_dict(torch.load(clip_model_name), strict=False)
def image_embeddings(self, image_file_path):
image_feature = self.model.forward_visual(image_file_path)
image_embeddings = image_feature[0].tolist()
return image_embeddings
def text_embeddings(self, text):
text_feature = self.model.forward_text(text)
text_embeddings = text_feature[0].tolist()
return text_embeddings
也可以选用其他的模型,比如:Chinese-CLIP, openCLIP。
2 向量数据库
在第二章节第1部分中,我们有提到使用torch.nn.functional.cosine_similarity简单比较两个图像间的余弦相似度。但是如果涉及到批量的图像数据,期望搜索最相似的topN图像数据时,出于性能的角度考虑,显然我们不能用暴力搜索的方式,一一去匹配相似度、再排个序返回。
这时,我们就需要向量数据库了。与传统数据库基于文本的精确匹配不同,向量数据库是以数学形式存储的向量数据集合。向量数据库能够将向量存储为高维点并进行检索。这些数据库增加了额外的功能,可以高效、快速地查找 N 维空间中的最近邻。这些功能通常由 k 最近邻(k-NN)索引提供支持,并使用分层可导航小世界(HNSW)和倒排文件索引(IVF)算法等算法构建。此外,向量数据库可以提供数据管理、容错、身份验证和访问控制以及查询引擎等其他功能。
通过将图像生成的向量索引到向量数据库中,我们在做检索时,就可以通过查询相邻向量来找到相似的目标图像了。这里笔者使用的是Chroma,其使用起来比较简单,新增、查询数据如下示例:
# my_chroma_db = MyChromaDB(‘./data/my_image_chroma/’, 'my_images')
class MyChromaDB:
def __init__(self, db_path, collection_name):
# 指定 Chroma 的数据库文件存储路径,如果数据存在,程序启动的时候会自动加载数据库文件。
self.client = chromadb.PersistentClient(path=db_path)
self.collection = self.client.get_or_create_collection(name=collection_name)
# 新增数据
def add_data(self, image: ImageRecord):
self.collection.add(
ids=[str(image.table_id)],
embeddings=[image.embeddings],
documents=[image.filename],
)
# 根据id查询数据
def get_by_id(self, image_id):
return self.collection.get(ids=[image_id], include=["embeddings"])
# 查询向量
def query(self, embeddings, count_limit):
return self.collection.query(query_embeddings=embeddings, n_results=count_limit)
3 web
web页面这里比较简单,笔者用的flask,提供下页面、查询接口、资源访问接口即可。这里简单列一下查询接口:
@app.post("/search")
def query():
data = request.json
print(f"query data{data}")
image_res = []
# 用户查询的关键词(searchType为text),或者图像的id(searchType为image)
keyword = str(data.get("keyword", ""))
search_type = data.get("searchType", "text")
if search_type == "image":
chroma_image_record = my_chroma_db.get_by_id(keyword)
embeddings = chroma_image_record["embeddings"]
else:
embeddings = my_clip_model.text_embeddings(keyword)
embeddings_query_result = my_chroma_db.query(embeddings, NUM_IMAGE_RESULTS) # {ids:[], distances:[]}
image_ids = embeddings_query_result["ids"][0]
distances = embeddings_query_result["distances"][0]
for i in range(0, len(image_ids)):
image_id = image_ids[i]
distance = distances[i]
image = my_sqlite3_db.query_by_id(image_id)
if image is not None:
image_res.append(convert_image_to_ui_data(image, distance))
return generate_resp("", image_res)
四 技术原理之向量篇
1 向量与特征
在深入了解CLIP前,我们需要先详细了解一下特征和向量的概念原理。我们先思考一个问题:在生活中,我们是如何区分各种物体种类的?
如果从理论角度上讲,这是因为我们识别不同事物之间不同的特征,进而能够识别种类。以区分不同种类的狗子为例,我们可以通过狗子的体型大小、毛发长度、鼻子长短等特征来区分。

如这张照片所示,我们可以按照体型分类:简单按照体型大小排序后,可以看到体型越大的狗越靠近坐标轴右边。这样,我们就能得到狗子体型特征的一维坐标和对应的数值,从 0 到 1 的数字中得到每只狗在坐标系中的位置。
然而单靠一个体型大小的特征并不够,像照片中哈士奇、金毛和拉布拉多的体型就非常接近,我们无法区分。所以我们需要依赖继续观察其它特征,例如毛发的长短。我们可以针对毛发的长短,建立第二的维度,这样每只狗对应一个二维坐标点,我们就能轻易的将哈士奇、金毛和拉布拉多区分开来。
但是仅靠体型、毛发长短,还是不够:这时仍然无法很好的区分德牧和罗威纳犬。我们可以继续再从其它的特征区分,比如鼻子的长短,这样就能得到一个三维的坐标系和每只狗在三维坐标系中的位置。如此往复,在这种情况下,只要特征足够多,就能够将所有的狗区分开来,最后就能得到一个高维的坐标系,也许我们想象不出高维坐标系长什么样,但是在数组中,我们只需要一直向数组中追加数字就可以了。
实际上,只要维度够多,我们就能够将所有的事物区分开来:从具体的山河日月、鸟兽鱼虫,到抽象的喜怒哀乐、悲欢离合,世间万物都可以用一个多维坐标系来表示,它们都在一个高维的特征空间中对应着一个坐标点。

这样,我们能用向量表示世间万物的特征,每个特征(特征不一定是狗子身高那种具体的,也可以是抽象的)就是一个向量的维度。
2 相似向量计算
和传统的数据匹配不同,向量数据的查询,多是查询与指定多维坐标位置(指定向量)接近的向量,是模糊的相似性计算。例如我们查询一只狗子具体是什么品种,我们知道了它的体型、毛发、鼻长、眼睛大小等等特征,我们先得到该狗子的特定向量,然后要在众多向量中找到最相似的一些。我们根据相似向量的狗子品种,来确定该狗子最终的品种。
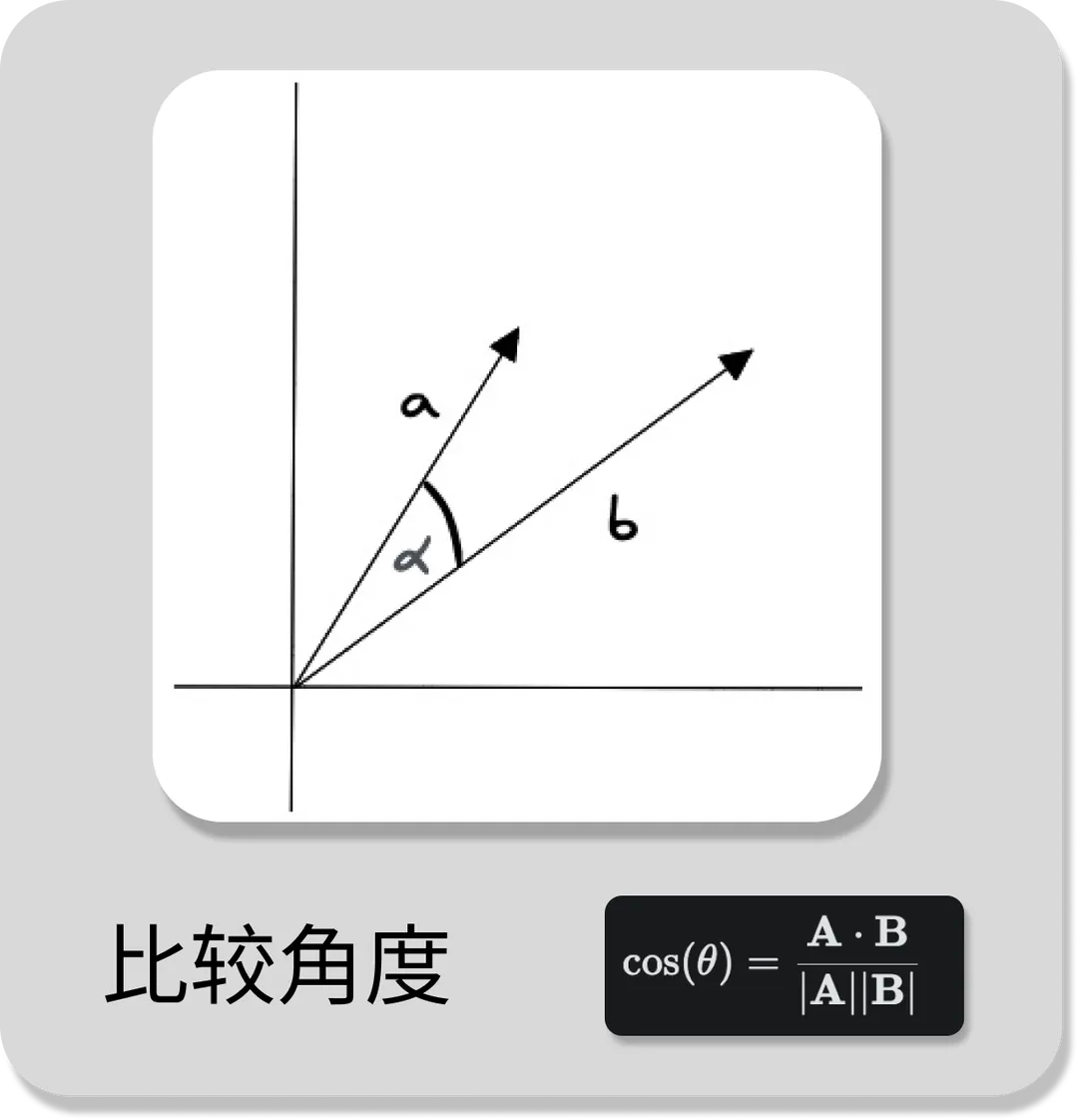
2.1 余弦相似度(Cosine Similarity)
余弦相似度是指两个向量之间的夹角余弦值,它的计算公式如图所示。其中,A 和 B 分别表示两个向量,·表示向量的点积,|A|和|B|分别表示两个向量的模长。若两个向量之间夹角越小,则向量越相似。
余弦相似度对向量的长度不敏感,只关注向量的方向,比较适用于高维向量的相似性计算。例如语义搜索和文档分类。
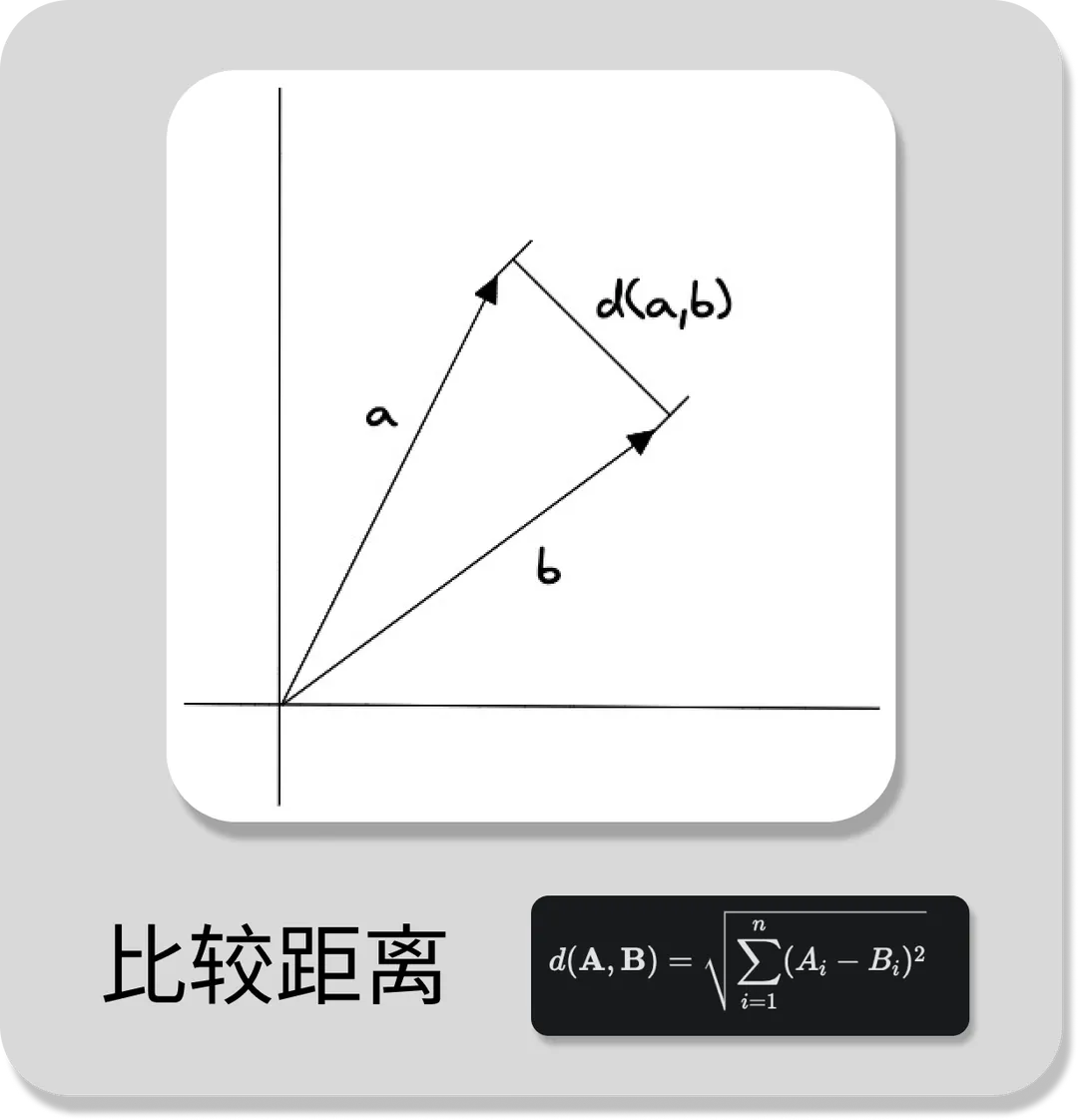
2.2 欧几里得距离(Euclidean Distance)
欧几里得距离是指两个向量之间的距离,它的计算公式如图所示。其中,A 和 B 分别表示两个向量,n 表示向量的维度。欧式距离越小表示向量的顶点之间越近,即向量之间更相似。
欧几里得距离算法的优点是可以反映向量的绝对距离,适用于需要考虑向量长度的相似性计算。例如推荐系统中,需要根据用户的历史行为来推荐相似的商品,这时就需要考虑用户的历史行为的数量,而不仅仅是用户的历史行为的相似度。
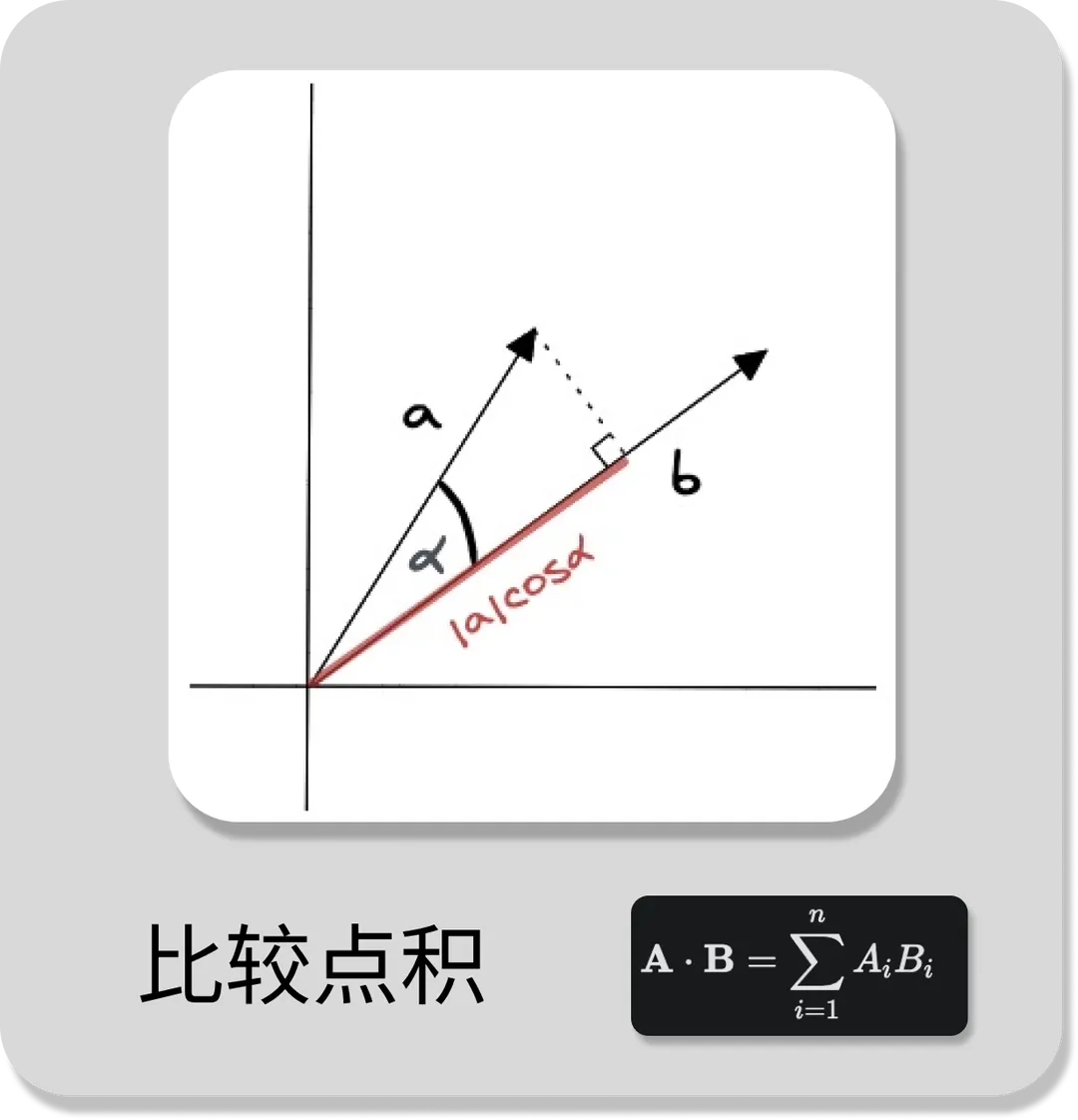
2.3 点积相似度 (Dot product Similarity)
余弦相似度是指两个向量之间的夹角余弦值,它的计算公式如图所示。其中,A 和 B 分别表示两个向量,n 表示向量的维度。
点积相似度算法的优点在于它简单易懂,计算速度快,并且兼顾了向量的长度和方向。它适用于许多实际场景,例如图像识别、语义搜索和文档分类等。但点积相似度算法对向量的长度敏感,因此在计算高维向量的相似性时可能会出现问题。
2.4 海明距离
严格来说,海明距离其实和向量没有太大关系,海明距离计算的是两个等长字符串对应位置字符不同的个数。
对于向量来说,海明距离可以看作是将一个向量变换成另一个向量所需要替换的坐标个数。
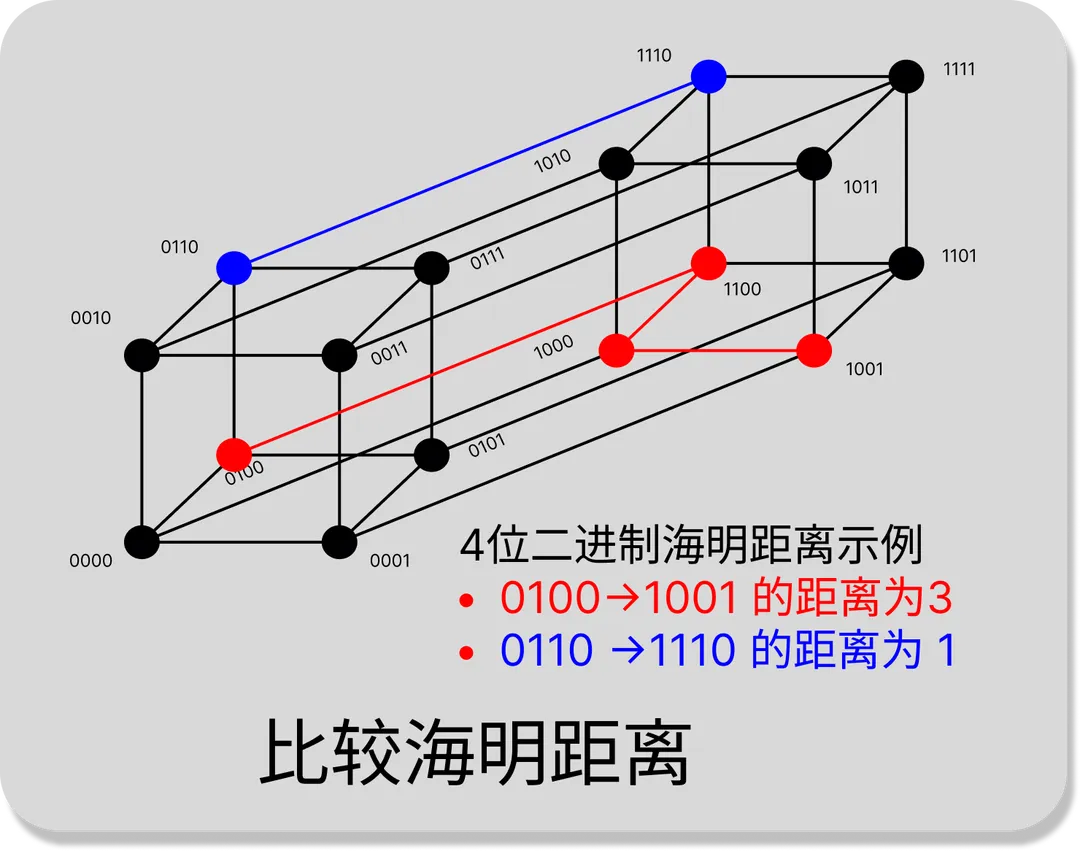
不同的距离计算公式反应的是向量不同维度的特征,都有其优点和缺点,需要开发者根据自己的数据特征和业务场景来选择。具体地,开发人员可以分别用几种公式进行召回率测试,看哪个召回率更高一些什么的。
3 向量检索
知道了向量相似性的比较方法(可以通过比较向量之间的距离来判断它们的相似度),我们还要对向量查询有方法论。不然的话,如果想要在一个海量的数据中找到和某个向量最相似的向量,我们需要对数据库中的每个向量进行一次比较计算。这样的计算量是非常巨大的,所以我们需要一种高效的算法来解决这个问题。
高效的搜索算法有很多,其主要思想是通过两种方式提高搜索效率:
- 减少向量大小——通过降维或减少表示向量值的长度。
- 缩小搜索范围——可以通过聚类或将向量组织成基于树形、图形结构来实现,并限制搜索范围仅在最接近的簇中进行,或者通过最相似的分支进行过滤。
对向量检索来说,通常有三类方法:基于树的方法、Hash方法、矢量量化方法。
3.1 基于树(Tree-based methods)
这类方法通过构建树结构来组织数据,以便快速检索。例如,KD树(k-dimensional tree)和R树(R-tree)是两种常见的基于树的数据结构,它们可以用来存储空间数据,以便进行快速的近邻搜索。基于树的方法适合于维度不是特别高的情况,因为在高维空间中,树结构的效率会因为“维度的诅咒”而大幅下降。
3.2 哈希方法(Hashing methods)
哈希方法通过哈希函数将高维向量映射到低维的哈希码上,使得相似的数据点在哈希空间中也相邻。局部敏感哈希(Locality-Sensitive Hashing, LSH)是一种著名的哈希方法,它能够保证在高维空间中距离相近的点在哈希后的低维空间中仍然相近。哈希方法通常适用于大规模数据集和高维数据的快速检索。
3.3 矢量量化方法(Vector Quantization methods)
矢量量化是一种通过将向量空间划分为有限数量的区域,并用这些区域的代表点(质心)来近似表示所有的点的方法。最著名的矢量量化方法是k均值算法(k-means),它将数据点聚类成k个簇,并用簇的质心来代表簇中的所有点。乘积量化(Product Quantization)和优化乘积量化(Optimized Product Quantization)是两种用于大规模相似性搜索的矢量量化技术。矢量量化方法适用于需要压缩数据以节省存储空间和加速检索的场景。
3.3.1 k均值算法(k-means)
我们可以在保存向量数据后,先对向量数据先进行聚类。
常见的聚类算法有 K-Means,它可以将数据分成 k 个类别,其中 k 是预先指定的。以下是 k-means 算法的基本步骤:
选择 k 个初始聚类中心。
将每个数据点分配到最近的聚类中心。
计算每个聚类的新中心。
重复步骤 2 和 3,直到聚类中心不再改变或达到最大迭代次数。
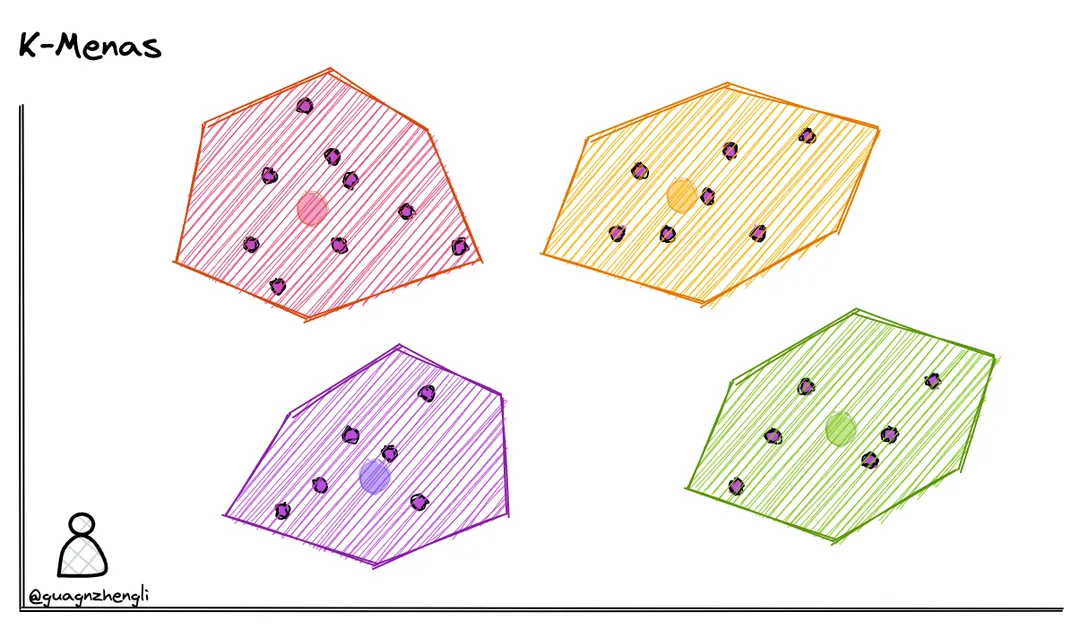
但是这种搜索方式也有一些缺点,例如在搜索的时候,如果搜索的内容正好处于两个分类区域的中间,就很有可能遗漏掉最相似的向量。
3.3.2 乘积量化(Product Quantization)
这里的乘积是指笛卡尔积(Cartesian Product),意思是指把原来的向量空间分解为若干个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化(Quantization)。这样每个向量就能由多个低维空间的量化code组合表示。
PQ是一种量化(quantization)方法,本质上是数据的一种压缩表达方法,所以该方法除了可以用在相似搜索外,还可以用于模型压缩,特别是深度神经网络的模型压缩上。
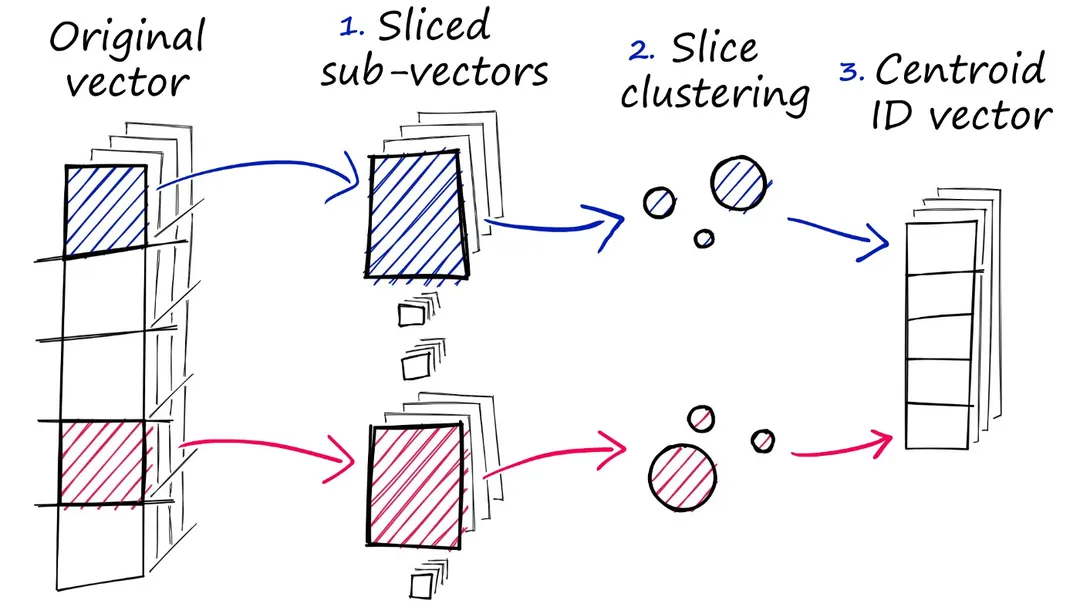
如图所示,一个128维的向量,可以分割为8个16维的低纬维度子向量,并分别对这8个16维的低维向量独立用kmeans算法做量化。在图中,假设16维的低维子向量需要256个聚类中心,我们用一个0~255的值去映射。这样,原先一个128维的向量,就可以用8个0~255的值,表示原始128维向量最终的量化编码值。
3.3.3 分层导航小世界(Hierarchical Navigable Small Worlds) (HNSW)
分层导航小世界(Layered Navigation Small World)是一种用于提升用户在复杂环境或大量信息中寻找目标内容时的导航效率和体验的设计方法。它借鉴了“小世界网络”(Small World Network)的概念,通过构建多层级的导航结构,使用户能够在有限的时间内快速找到所需信息。因为不好进行文字上的描述,这里推荐这歌视频 HNSW for Vector Search Explained and Implemented with Faiss (Python) 及其博客 HNSW
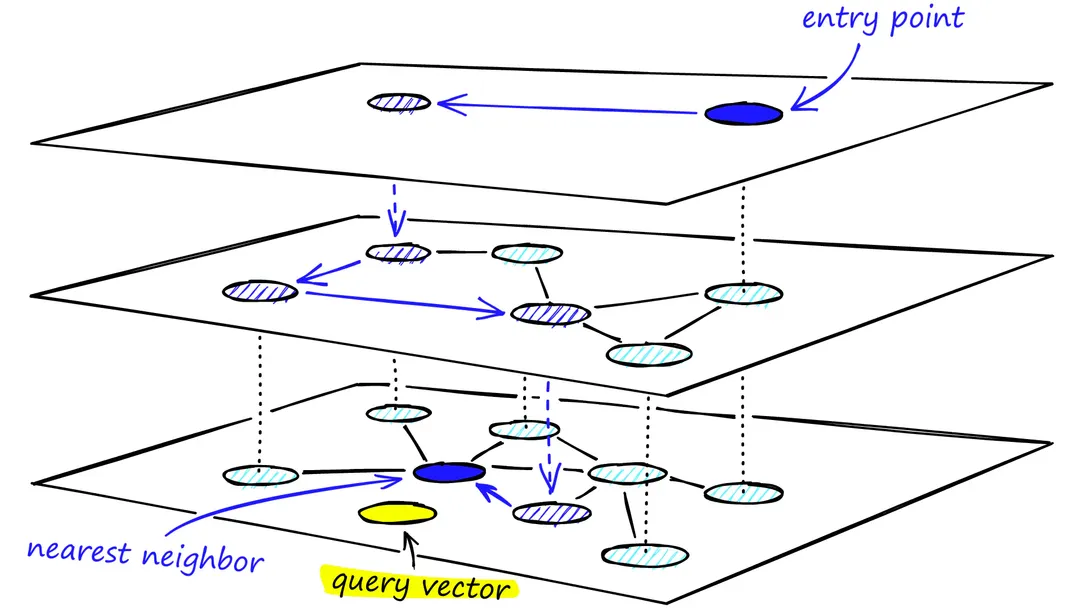
4 过滤 (Filtering)
在实际的业务场景中,往往不需要在整个向量数据库中进行相似性搜索,而是通过部分的业务字段进行过滤再进行查询。所以存储在数据库的向量往往还需要包含元数据,例如用户 ID、城市ID等信息。这样就可以在搜索的时候,根据元数据来过滤搜索结果,从而得到最终的结果。
为此,向量数据库通常维护两个索引:一个是向量索引,另一个是元数据索引。然后,在进行相似性搜索本身之前或之后执行元数据过滤,但无论哪种情况下,都存在导致查询过程变慢的困难。
过滤过程可以在向量搜索本身之前或之后执行,但每种方法都有自己的挑战,可能会影响查询性能:
- Pre-filtering:在向量搜索之前进行元数据过滤。虽然这可以帮助减少搜索空间,但也可能导致系统忽略与元数据筛选标准不匹配的相关结果。
- Post-filtering:在向量搜索完成后进行元数据过滤。这可以确保考虑所有相关结果,在搜索完成后将不相关的结果进行筛选。
- 为了优化过滤流程,向量数据库使用各种技术,例如利用先进的索引方法来处理元数据或使用并行处理来加速过滤任务。平衡搜索性能和筛选精度之间的权衡对于提供高效且相关的向量数据库查询结果至关重要。
5 向量数据库
一些向量数据库对比(数据截止到2024.06中旬)。
| 向量数据库 | URL | GitHub Star | Language | Cloud |
|---|---|---|---|---|
| chroma | https://github.com/chroma-core/chroma | 13.2K | Python | ❌ |
| milvus | https://github.com/milvus-io/milvus | 27.9K | Go/Python/C++ | ✅ |
| pinecone | https://www.pinecone.io/ | ❌ | ❌ | ✅ |
| qdrant | https://github.com/qdrant/qdrant | 18.6K | Rust | ✅ |
| typesense | https://github.com/typesense/typesense | 18.5K | C++ | ❌ |
| weaviate | https://github.com/weaviate/weaviate | 10.1K | Go | ✅ |
3.5.1 qdrant
QDrant向量数据库可以用docker快速安装、部署,如下所示($(pwd)/qdrant_storage指数据的存储路径,可以替换为自己具体期望的目录):
docker pull qdrant/qdrant
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant
之后,我们可以集成依赖(支持python/ts/rust/java/c#),或者用RestfulAPI的方式,进行数据库的增删改查工作。这是文档地址(内含使用示例)。
- 集成依赖: https://qdrant.tech/documentation/quick-start/
- Restful API: https:/.qdrant.tech-reference
QDrant Client Libraries
| Client | Repository | Installation |
|---|---|---|
 | Python | pip install qdrant-client |
 | Typescript | npm install @qdrant/js-client-rest |
 | Rust | cargo add qdrant-client |
 | Go | go get github.com/qdrant/go-client |
 | .NET | dotnet add package Qdrant.Client |
 | Java | Available on Maven Central |
3.5.2 chroma
python的新增、查询数据如下示例。想要了解更多可以参考文档: https://docs.trychroma.com/getting-started
# my_chroma_db = MyChromaDB(‘./data/my_image_chroma/’, 'my_images')
class MyChromaDB:
def __init__(self, db_path, collection_name):
# 指定 Chroma 的数据库文件存储路径,如果数据存在,程序启动的时候会自动加载数据库文件。
self.client = chromadb.PersistentClient(path=db_path)
self.collection = self.client.get_or_create_collection(name=collection_name)
# 新增数据
def add_data(self, image: ImageRecord):
self.collection.add(
ids=[str(image.table_id)],
embeddings=[image.embeddings],
documents=[image.filename],
)
# 根据id查询数据
def get_by_id(self, image_id):
return self.collection.get(ids=[image_id], include=["embeddings"])
# 查询向量
def query(self, embeddings, count_limit):
return self.collection.query(query_embeddings=embeddings, n_results=count_limit)
ChromaDB Language Clients
| language | client |
|---|---|
| Python | ✅ chromadb (by Chroma) |
| Javascript | ✅ chromadb (by Chroma) |
| Ruby | ✅ from @mariochavez |
| Java | ✅ from @t_azarov |
| Go | ✅ from @t_azarov |
| C# | ✅ from @microsoft |
| Rust | ✅ from @Anush008 |
| Elixir | ✅ from @3zcurdia |
| Dart | ✅ from @davidmigloz |
| PHP | ✅ from @CodeWithKyrian |
| PHP (Laravel) | ✅ from @HelgeSverre |
五 技术原理之Transformer篇
1 简介
Transformer 模型由 Vaswani 等人在 2017 年提出,彻底改变了自然语言处理(NLP)领域。与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer 模型完全基于注意力机制(Attention Mechanism),因此能够更高效地处理长序列数据。
Transformer 模型由编码器(Encoder)和解码器(Decoder)组成。编码器和解码器各自由多个相同的层(Layer)堆叠而成。本文将详细介绍 Transformer 模型的Encoder、Decoder。
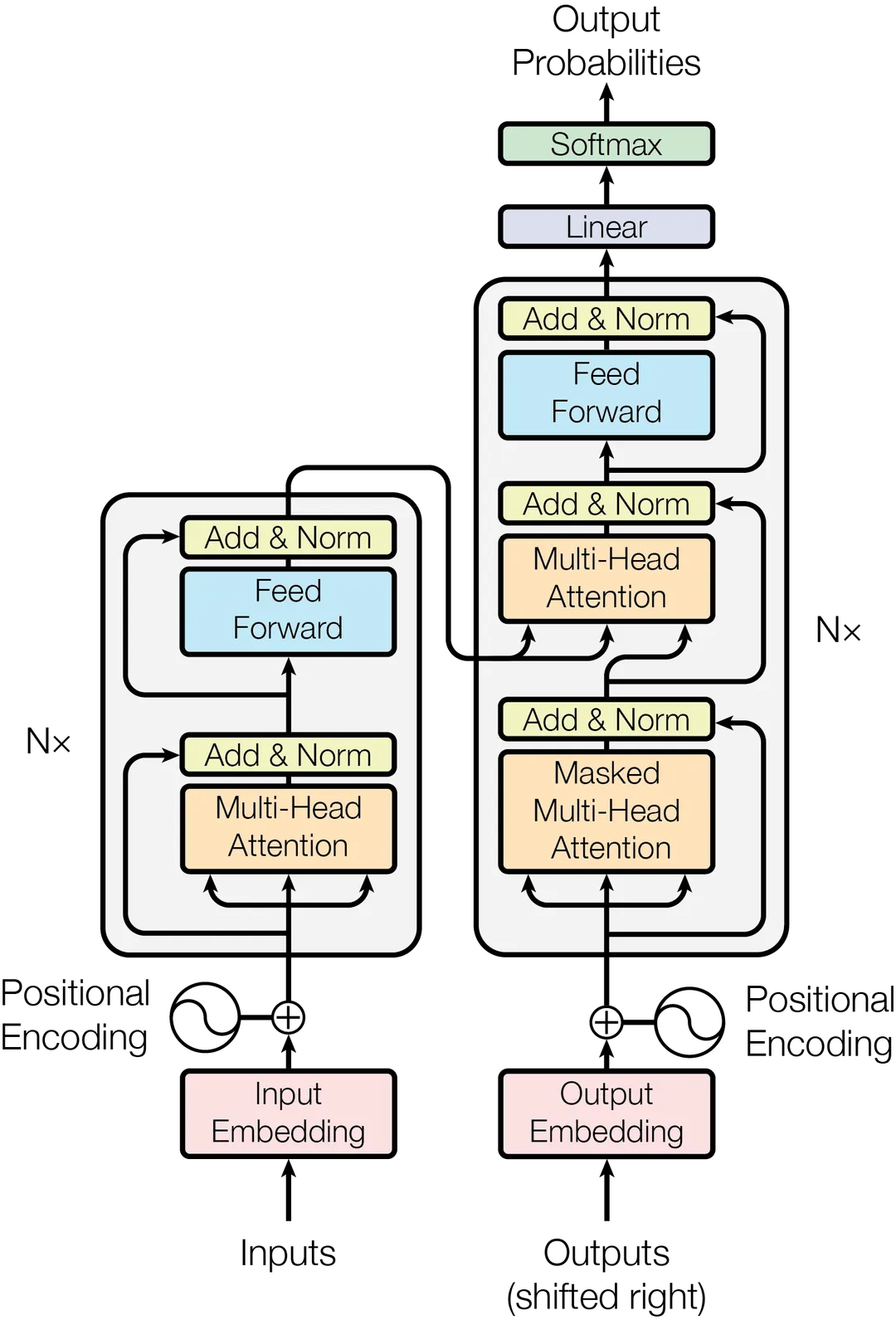
2 Encoder
Transformer的Encoder部分,关键步骤可以简化为下述四个步骤:
- Word Embedding: 将词汇转为机器认识的向量,同时保留词汇之间的关系。
- Positional Encoding:引入词汇的位置信息,从而能区分、认识句子。
- Self-Attention:引入句子中词汇间的依赖信息,从而能得知词汇间的代指关系等信息。
- Residual Connections:残差连接有助于训练,防止梯度爆炸/消失。
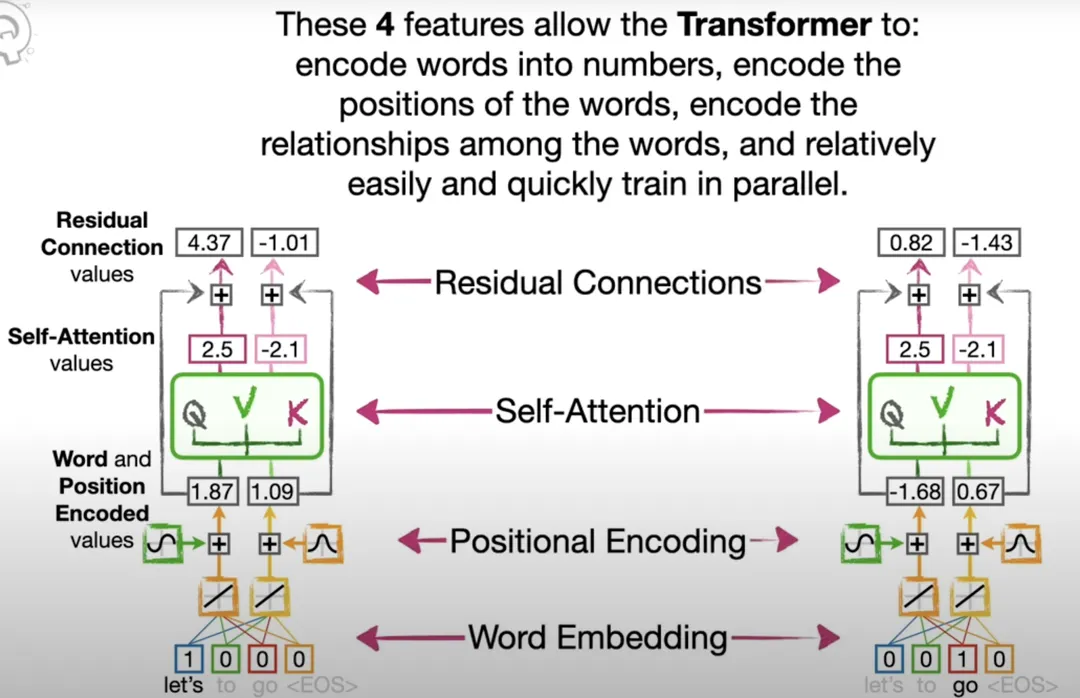
2.1 Word Embedding
Word Embedding是一种将词语或短语从词汇表中映射到向量空间的技术。这种映射是通过训练大量文本数据学习得到的,训练后的词向量可以捕捉到词语之间的语义和语法关系(白话的概述,可参考:第四章 技术原理之向量篇的第1部分向量与特征)。向量的每个维度代表一个分类特征,可以进行聚合分类。如下图,代表简化的二维,接近的事物期望被分配到向量相似度接近的位置:

其中,如何构建出Word Embedding呢?这里以Word2Vec为例,在数据预处理之后,会开始训练。在训练开始时,会为每个词随机初始化一个向量。这些向量的维度是一个超参数,可以根据需要进行调整。Word2Vec有两种主要的训练模型用来调整最终向量:
- Skip-gram:算法试图预测给定词周围的上下文词。给定一个词后,其目标是最大化周围上下文词的条件概率。通过优化损失函数(如负对数似然损失),不断调整词向量以减小预测误差。
- CBOW(Continuous Bag of Words):算法试图根据上下文词预测给定词。给定上下文词后,目标是最大化中心词的条件概率。同样通过优化损失函数来训练词向量。
在训练过程中,可以通过一些评估指标来检查词向量的质量。如相似度测试,可以通过计算词语之间的余弦相似度来评估模型的效果。或者用类比推理最近邻词,查找与某个词最相似的词。如果效果不佳,可以调整超参数或改进训练数据。
训练好的 Word2Vec 模型,可以将词向量用于各种自然语言处理任务,如文本分类、情感分析、机器翻译等。这些词向量能够捕捉到词语之间的潜在关系,从而提高模型的性能。
2.2 Positional Encoding
Word Embedding 能够捕捉到词语之间的潜在关系,也就是能够读懂词汇。但是对于一个句子来说,词汇的顺序并没有被 Word Embedding 表达出来。如果想让机器读懂一个句子,还需要词汇的位置信息。
Positional Encoding 是一种将位置信息编码到词向量中的方法。它通过为每个位置生成一个固定的向量,并将其与词向量相加,从而为模型提供位置信息。
这里Transformer通过预定义位置计算函数来实现的,具体实现采用的正弦和余弦函数。对于序列中的第 ( pos ) 个位置和词向量的第 ( i ) 个维度,Positional Encoding 的计算公式如下:
对于位置 (pos) 和维度 (i),Positional Encoding 的计算公式如下(正弦和余弦函数的周期性使得不同位置的编码具有独特性,而通过不同频率的正弦和余弦函数,可以捕捉到不同粒度的位置信息):
$$
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d}}}\right)
$$
$$ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d}}}\right) $$
其中:
pos是位置索引。i是维度索引。d是模型的维度。
之后,Position Encoding 会与 Word Embedding 相加(Position Encoding拼接Word Embedding的话,会将维度增加)。如下示例:
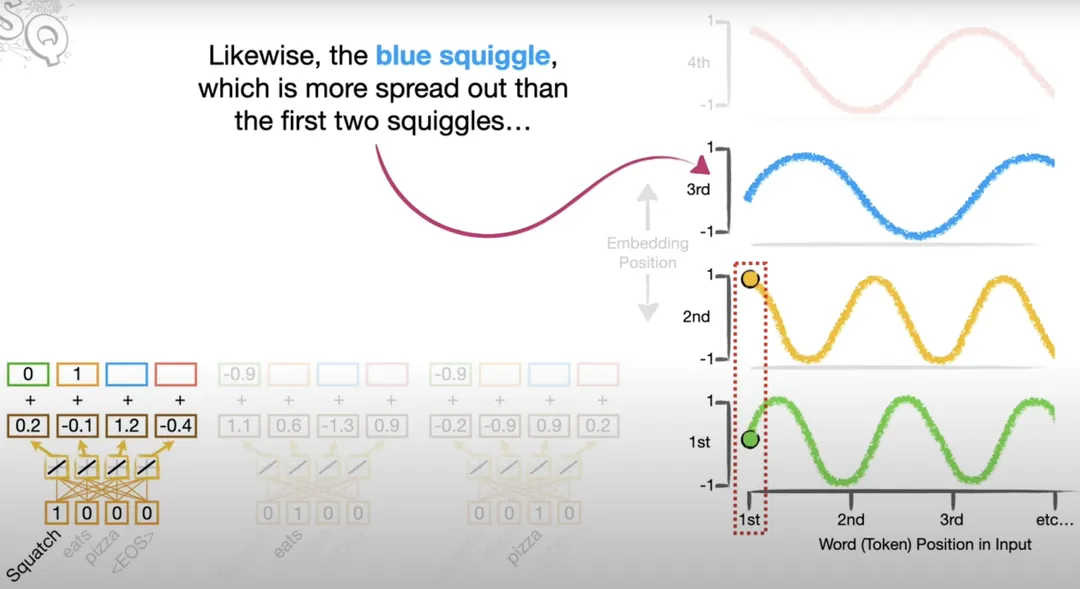
2.3 Self-Attention
Self-Attention 是一种特殊的注意力机制,它在同一个序列中计算每个位置与其他位置的相关性。这使得模型能够在编码或解码过程中同时关注序列中的所有位置,从而捕捉到全局的依赖关系。比如下面这句话,利用其可以判断“it”对其他词汇的依赖关系,得到“pizza”对“it”的影响对大,从而得知这里的“it”代指“pizza”(而不是“oven”)。

Self-Attention 的计算公式可以表示为 $$ Attention(𝑄,𝐾,𝑉) = \text{Softmax}\left(\frac{QK^T} {\sqrt{d_k}}\right)\text{V} $$ 其具体步骤是,对于输入一句话各个词汇的嵌入数据,分别通过三个不同的线性变换,得到不同词汇的查询Q(Query)、键K(Key)和值V(Value)矩阵。然后对于某个词汇,计算注意力得分,过程是结合其他词汇的K跟自己的Q,得到新的值。然后对于K跟Q得到的新的值,通过SoltMax归一化得到注意力权重。最终使用注意力权重对值矩阵 ( V ) 进行加权求和,得到最终的 Self-Attention 输出。
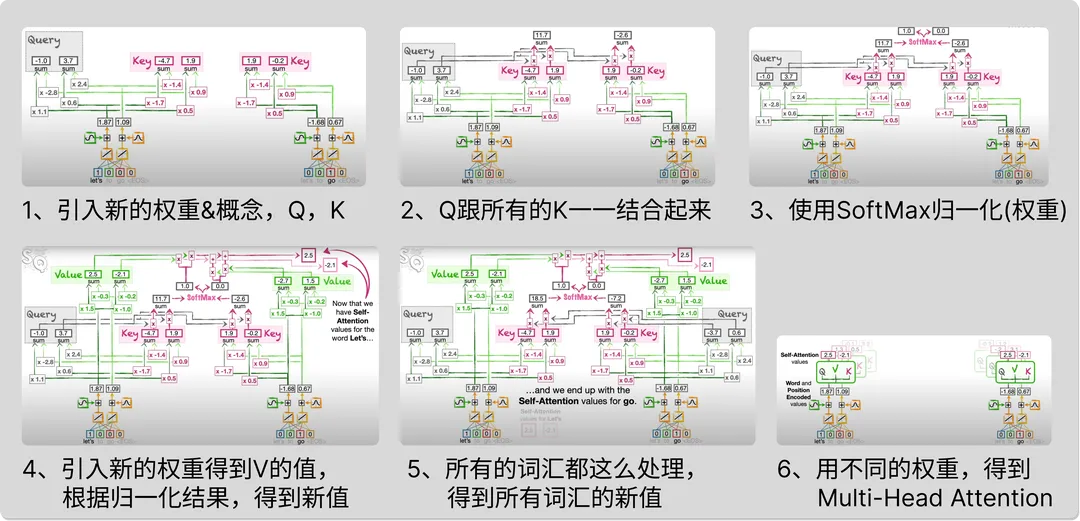
为了增强模型的表达能力,Transformer 引入了多头自注意力机制(Multi-Head Self-Attention)。具体来说,将查询、键和值矩阵分成多个头(head),每个头独立计算注意力,然后将所有头的输出拼接起来,并通过一个线性变换得到最终输出。
在 Transformer 模型中,Self-Attention 机制被广泛应用于编码器和解码器的每一层。编码器中的 Self-Attention 使得每个词能够关注输入序列中的所有其他词,而解码器中的 Self-Attention 则使得每个词能够关注解码器输出序列中的所有其他词。
2.4 Residual Connections
Residual Connections 是一种在深度神经网络中引入的技术,最早由 He 等人在 ResNet(Residual Networks)中提出。它通过在层与层之间添加直接的跳跃连接(skip connections),使得信息能够更容易地在网络中传播,从而缓解梯度消失和梯度爆炸问题。
关于其计算公式。假设某一层的输入为 ( x ),经过一系列变换(如线性变换和激活函数)后的输出为 ( F(x) )。在引入 Residual Connections 后,该层的输出变为: 𝑦=𝐹(𝑥)+𝑥 其中,( F(x) ) 表示该层的变换函数,( x ) 表示输入。
在 Transformer 模型中,Residual Connections 被广泛应用于编码器和解码器的每一层。具体来说,每一层的输出不仅包含当前层的变换结果,还包含上一层的输入信息。
2.5 Transformer 前馈神经网络(Feed-Forward Neural Network)
在上面2.1~2.4步骤中,每个位置的特征向量是通过与其他位置的特征向量的加权和矩阵运算来计算得到的,这种变化可能难以捕捉到复杂的非线性关系。
前馈神经网络,是一种单向传输的多层结构网络,由一个或多个线性变换和非线性激活函数组成。
在Transformer中,前馈神经网络通过两个线性变换和一个非线性激活函数,对每个位置的表示进行独立的变换。这种设计使得模型能够捕捉到更复杂的特征,从而提升其表达能力。
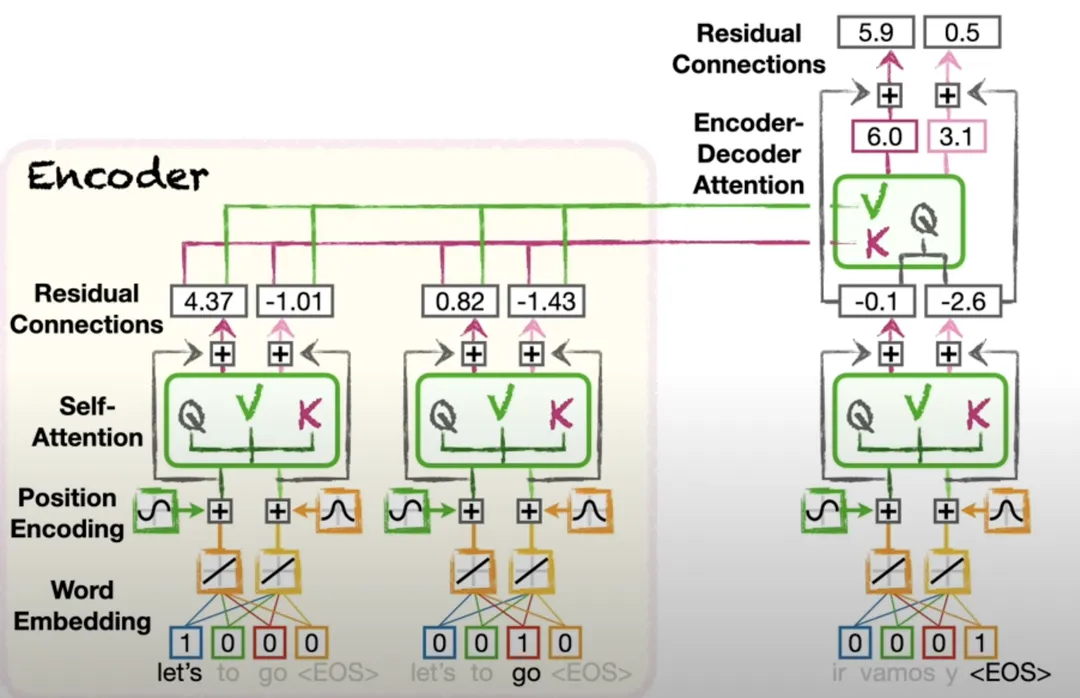
3 Decoder
3.1 自注意力机制
这里主要指以下两种注意力机制,不再赘述:
掩码多头自注意力机制:捕捉解码器输出序列中的依赖关系。
编码器-解码器注意力机制:捕捉编码器输出与解码器输入之间的依赖关系。
3.2 前馈神经网络
这里类似 2.5 前馈神经网络(Feed-Forward Neural Network),对每个位置的表示进行独立的非线性变换。
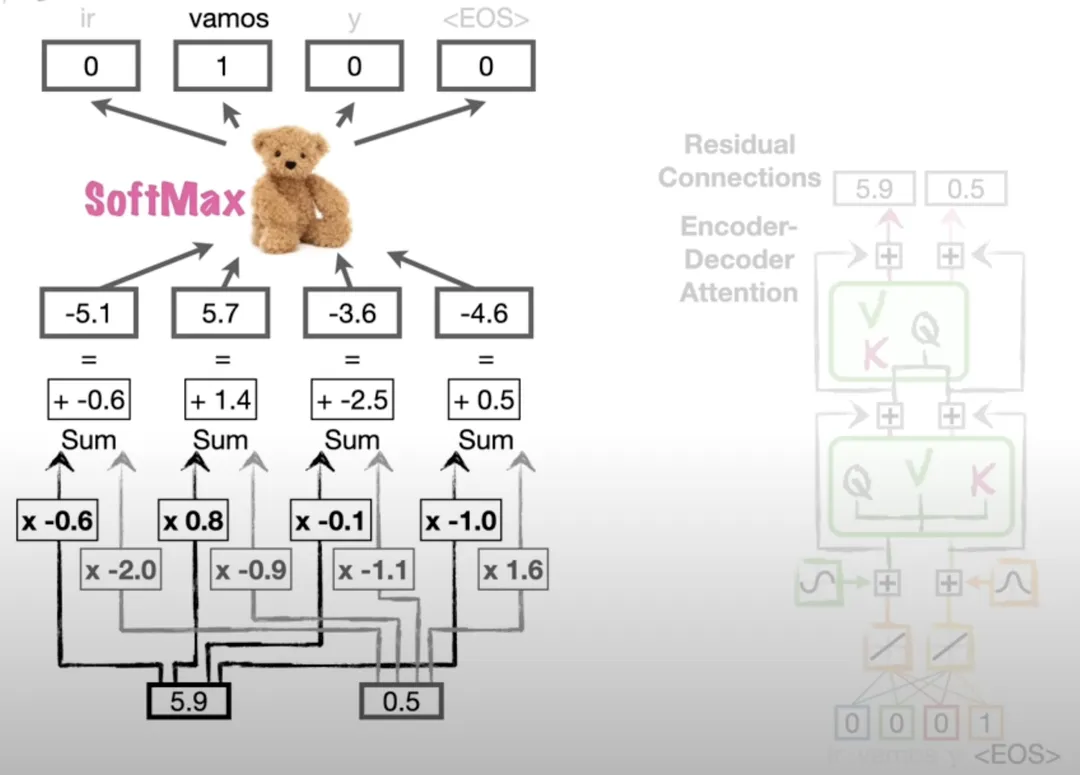
3.3 全连接层
这里引入全连接层,以计算出此步骤最终要翻译出的结果是哪个词汇。
3.4 计算各个词汇得到整个句子
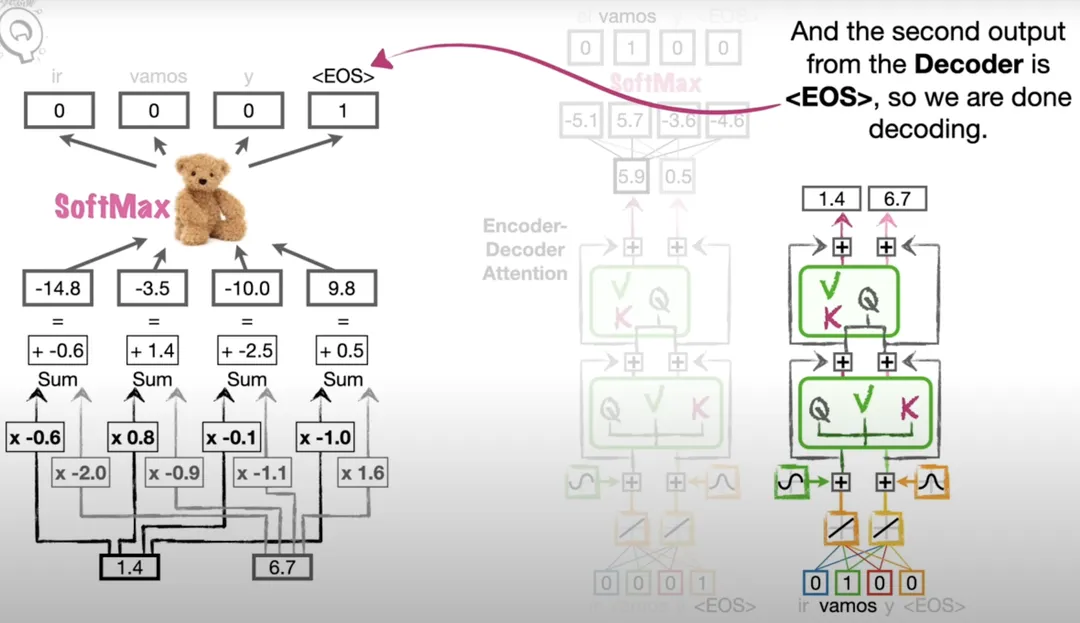
以“let’s go.”翻译成西班牙语为例,会先由句子结尾EOS得到vamos,之后会由vamos开始继续翻译下一个位置的词汇,得到EOS的概率最大。最终,“let’s go.”翻译成了“vamos.”。
六 技术原理之Vision Transfomer篇
1 简介
在计算机视觉领域,Vision Transformer (ViT) 是一种新兴的模型架构,它将 Transformer 模型的强大能力引入到图像处理任务中。ViT 由 Google Research 团队在 2020 年提出,并在多个视觉任务中取得了显著的性能提升。本文将详细介绍 Vision Transformer 的基本结构、核心组件及其应用。
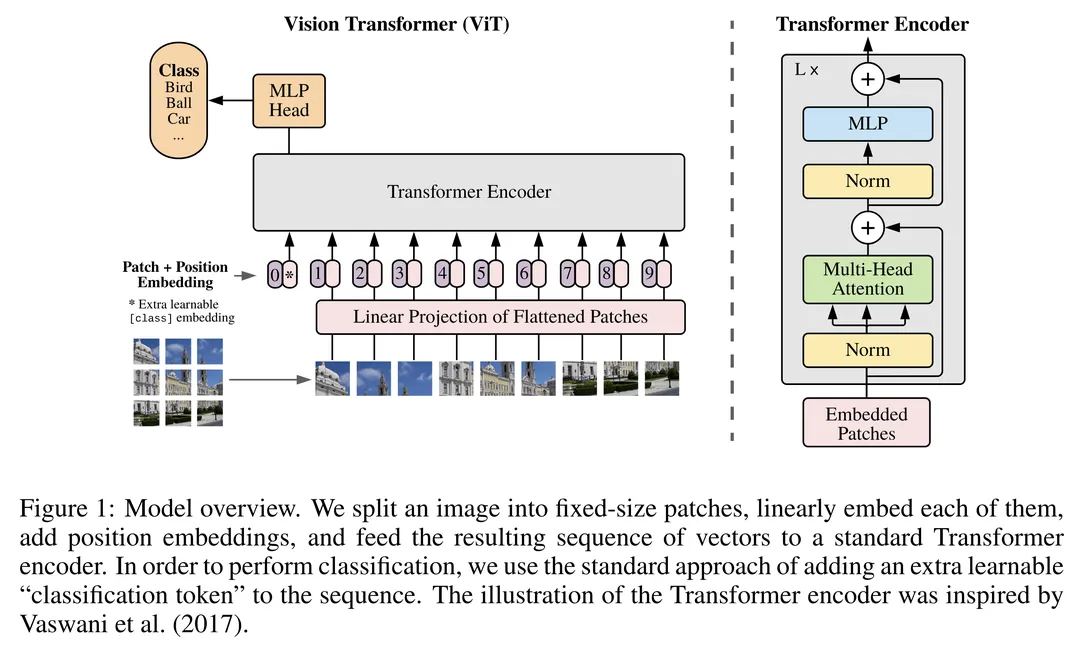
Transformer 模型通过自注意力机制(Self-Attention Mechanism),能够高效地捕捉序列中的全局依赖关系。ViT 将这一优势引入到图像处理任务中,从而克服了 CNN 的一些局限性(局部卷积核捕捉图像特征,难以捕捉全局依赖关系;多层卷积逐步提取高层次特征,可能导致信息丢失)。
ViT 的基本结构与原始 Transformer 模型类似,但在输入处理和位置编码上有所不同。ViT 的主要步骤包括图像分块、线性嵌入、位置编码、Transformer 编码器等。
2 步骤
这里简单介绍ViT的一些步骤,动态流程可以参考此动图。
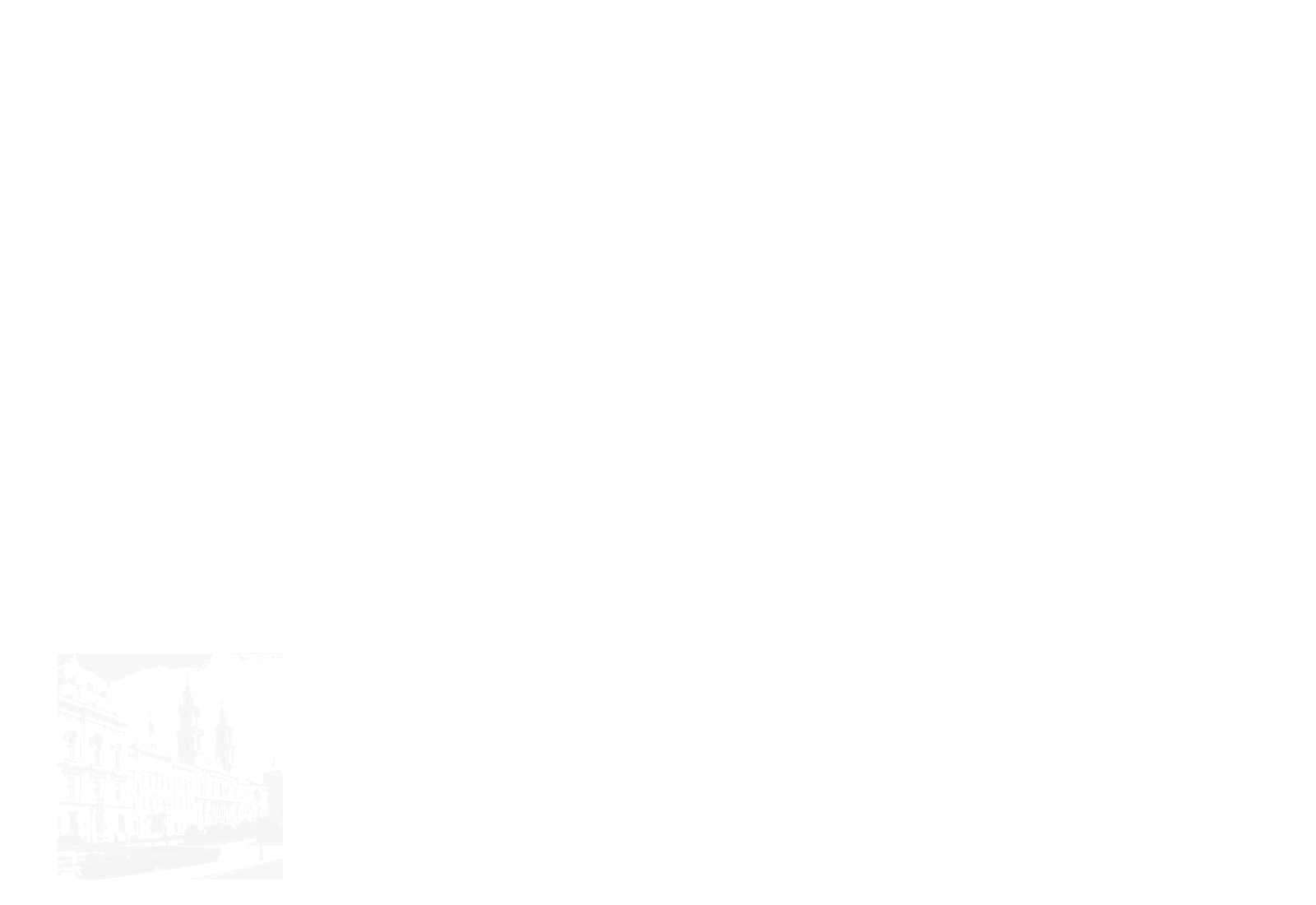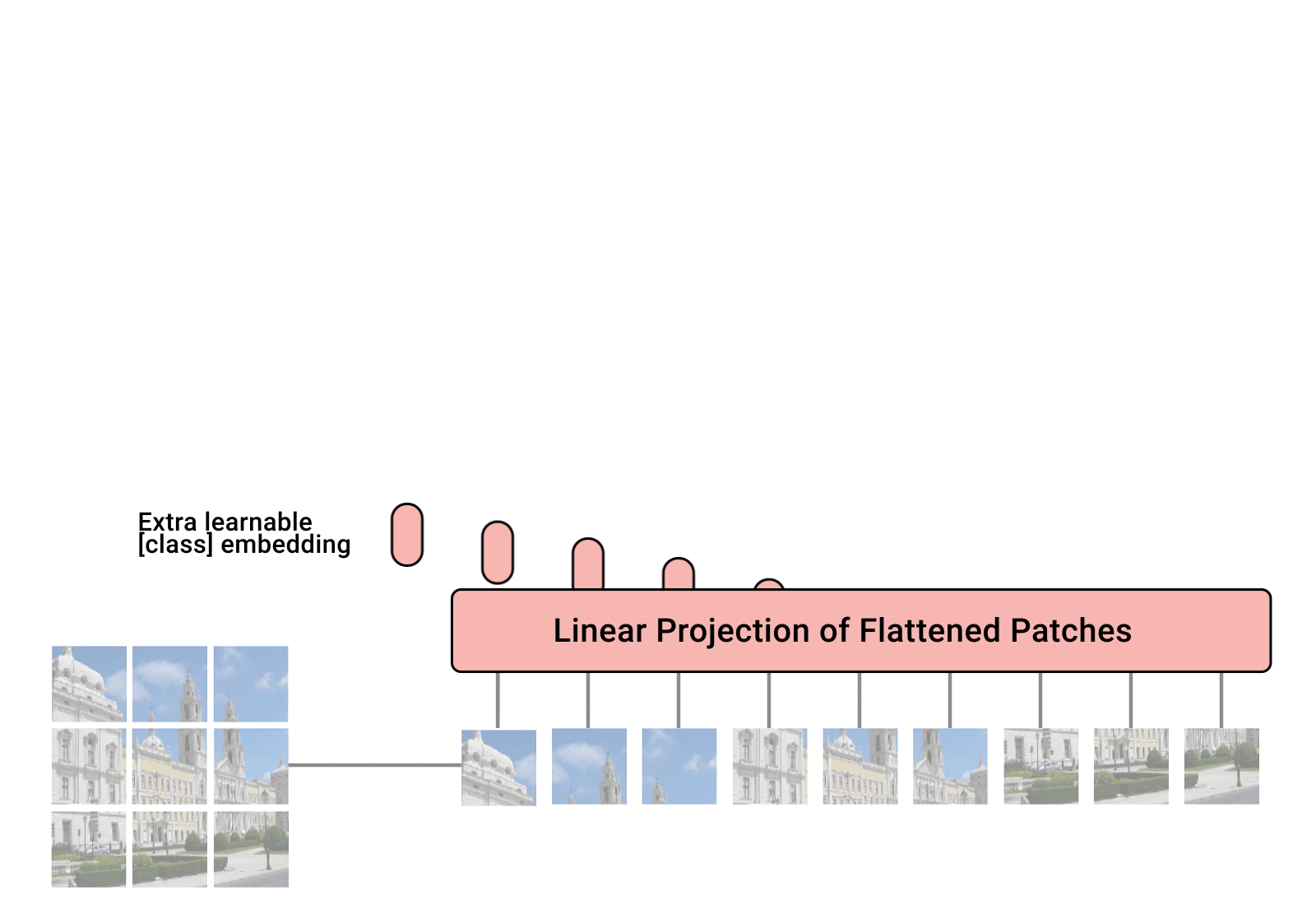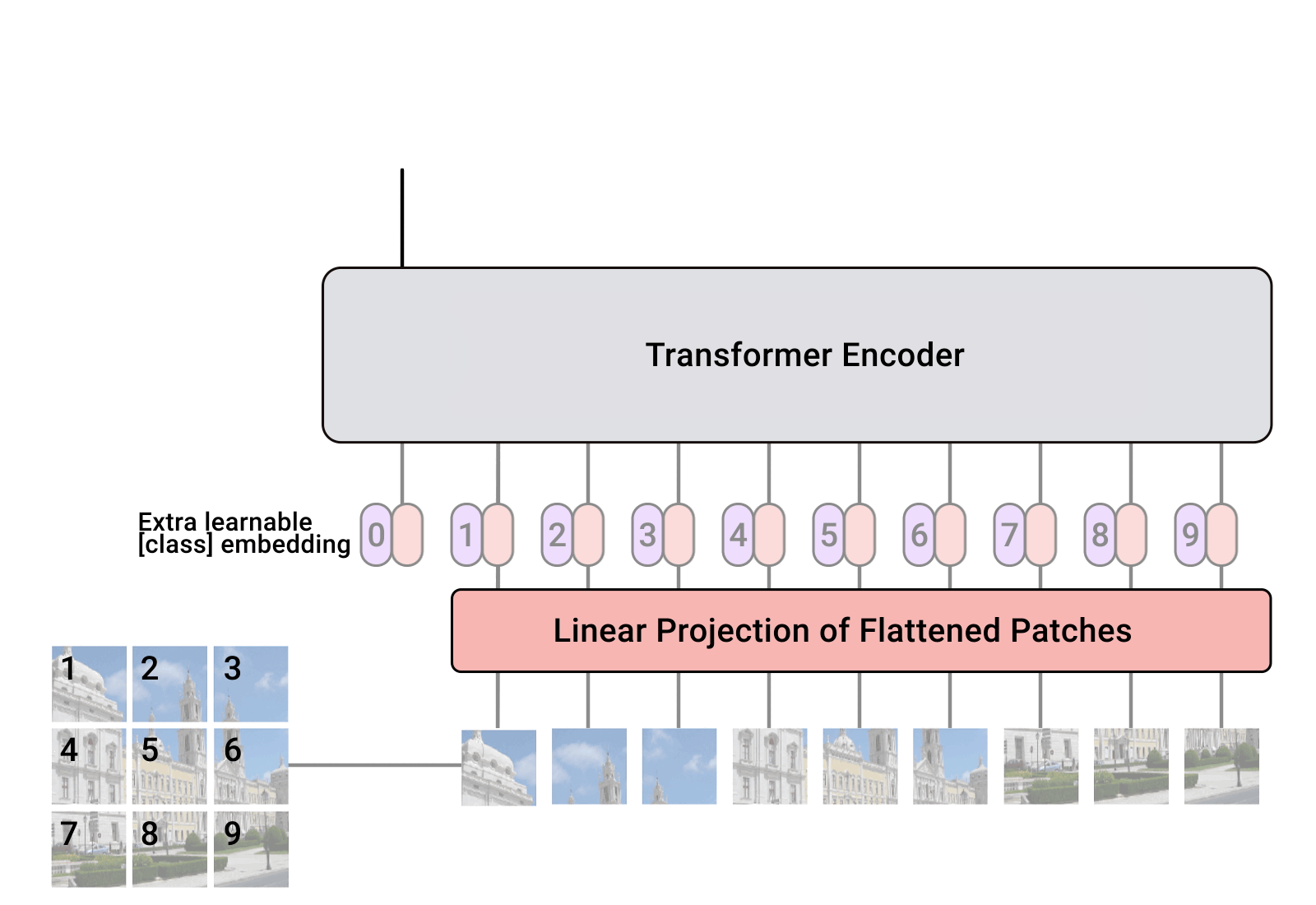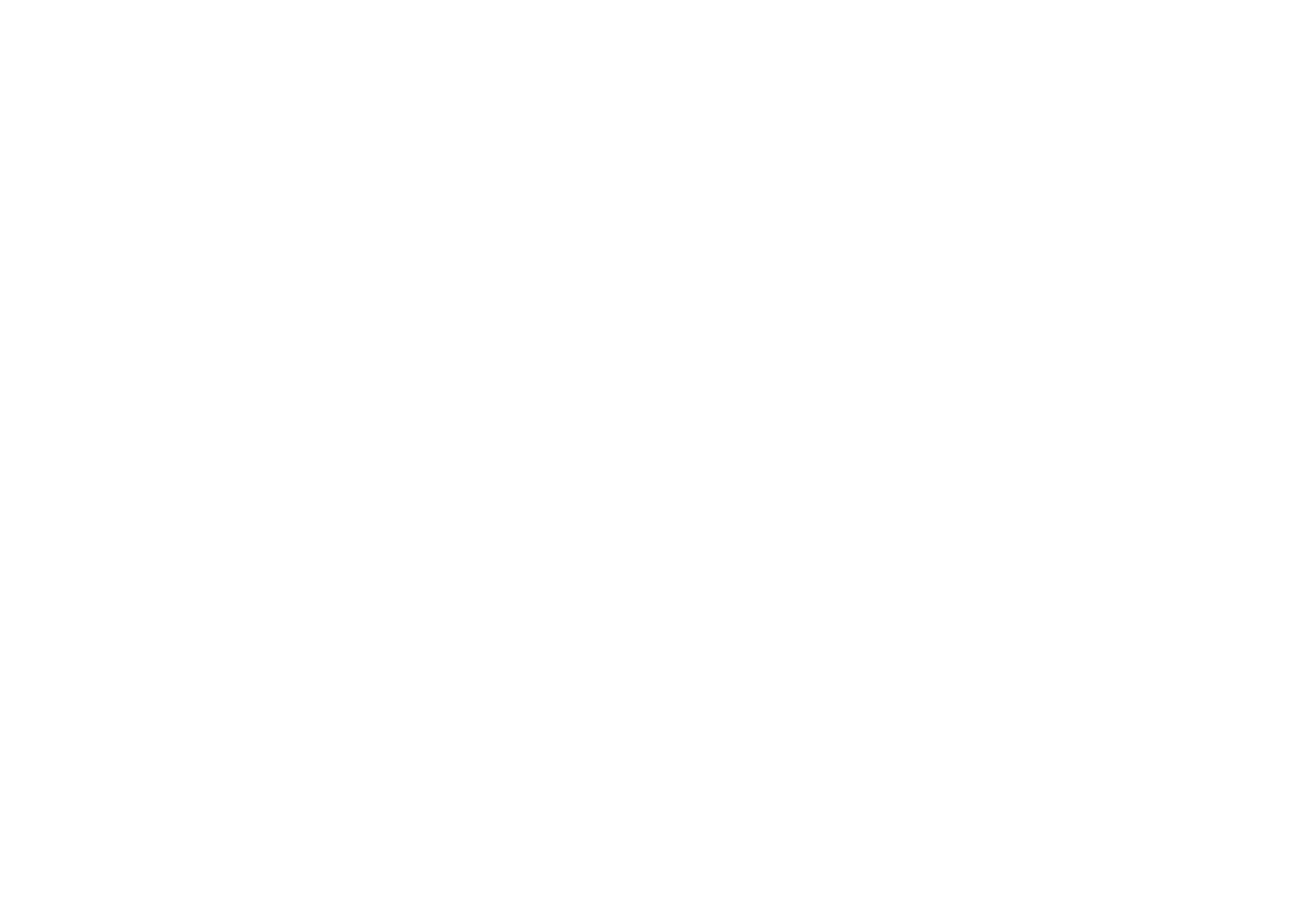
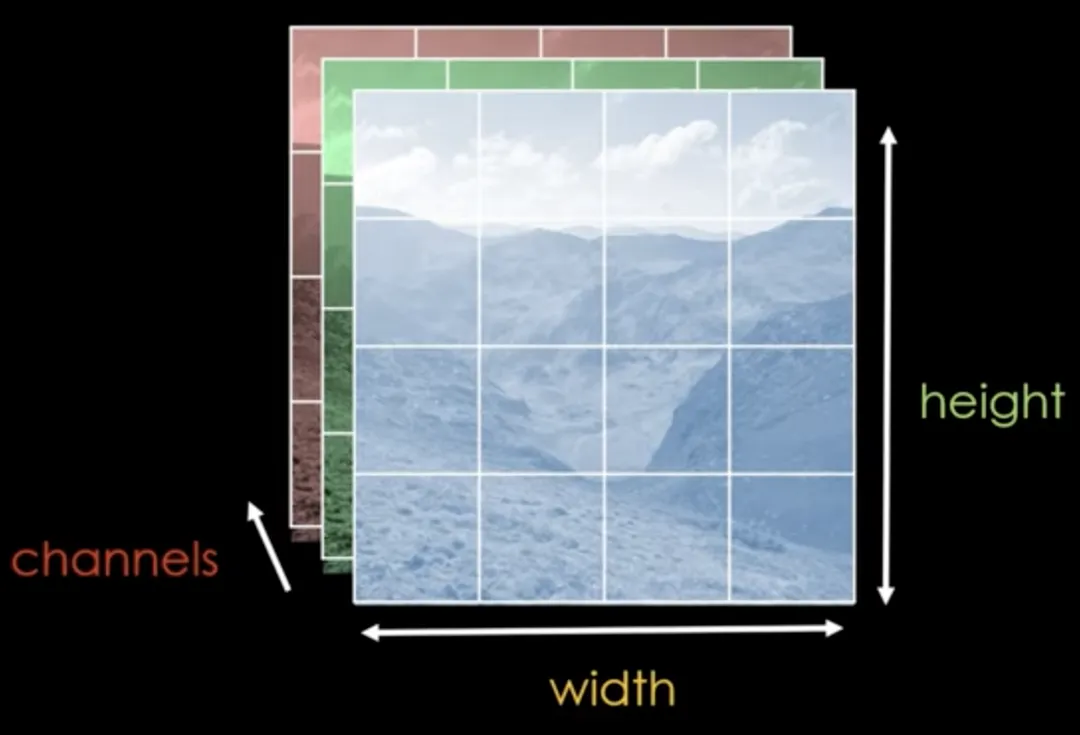
2.1 图像分块(Patch Embedding) & 线性嵌入(Linear Embedding)
对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到 (224/16)^2=14^2 =196个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积**[224, 224, 3]** -> [14, 14, 768],然后把H以及W两个维度展平即可**[14, 14, 768] -> [196, 768]**,此时正好变成了一个二维矩阵,正是Transformer想要的。

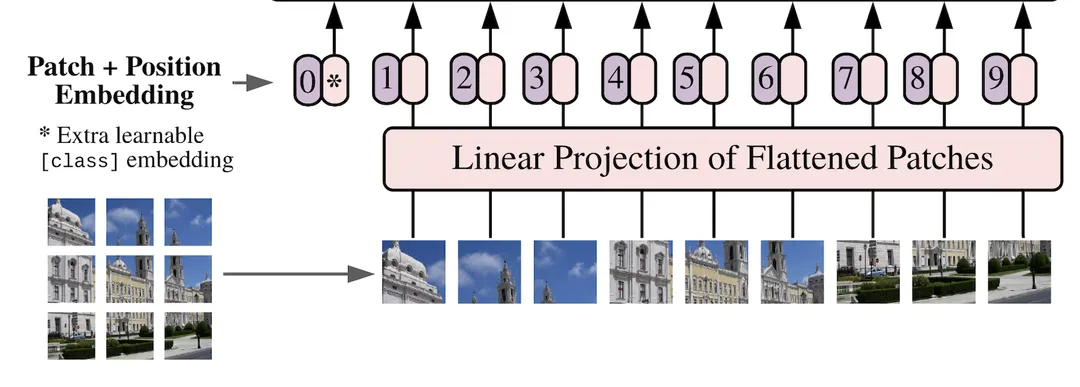
2.2 位置编码(Positional Encoding) & CLASS Token
在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。 在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。
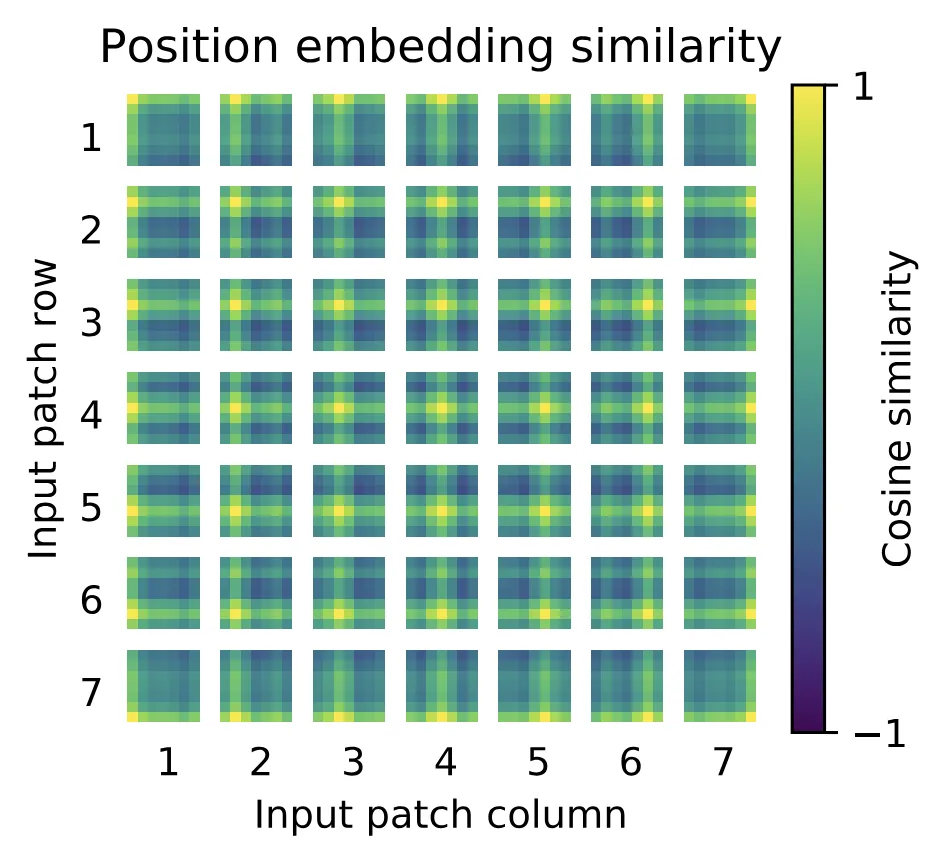
关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是**[197, 768]**。
2.3 Transformer 编码器
将嵌入后的图像块序列输入到多个 Transformer 编码器层中。每个编码器层包含多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Neural Network),并在每个子层之后添加残差连接(Residual Connections)和层归一化(Layer Normalization)。
这里的注意力机制,从视觉上,可以按照下图进行直观理解。

七 技术原理之clip代码篇
这里简介,可以直接参考下面的引用:
CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing for the task, similarly to the zero-shot capabilities of GPT-2 and 3. We found CLIP matches the performance of the original ResNet50 on ImageNet “zero-shot” without using any of the original 1.28M labeled examples, overcoming several major challenges in computer vision.
CLIP的主要步骤,可以参考此视频。 !videoclip_process_demo.mp4
1 主函数
CLIP模型主函数在源码model.py文件中,如下图所示:
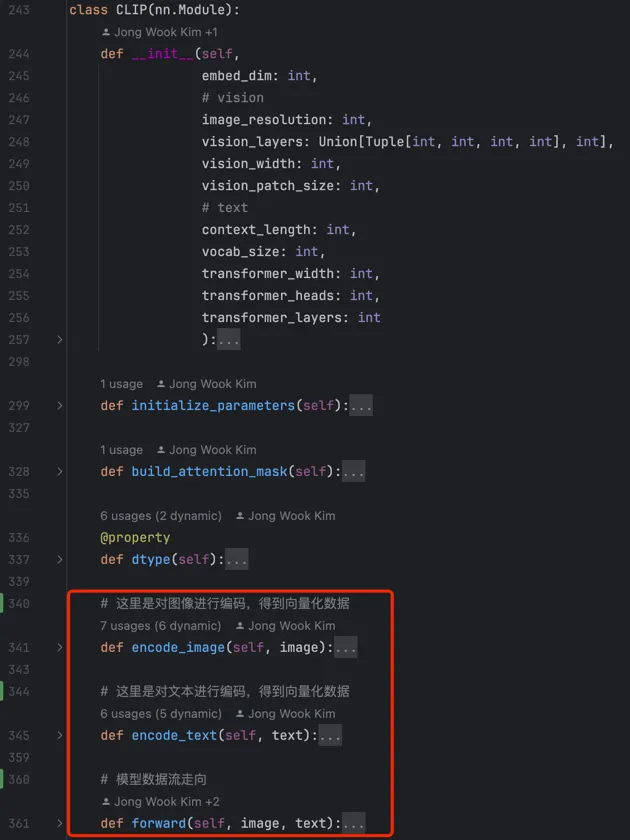
2 image encode 代码
2.1 CLIP主函数部分
# 这里是对图像进行编码,得到向量化数据
def encode_image(self, image):
return self.visual(image.type(self.dtype))
CLIP使用图像编码有ResNet结构与VisionTransformer,前者是CNN方式,后者是transformer方式,我将以transformer方式解读,如下代码:
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else:
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
2.2 ViT部分
这里的核心步骤,是forward函数。这里在下面源码加了注释:
class VisionTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
scale = width ** -0.5
self.class_embedding = nn.Parameter(scale * torch.randn(width))
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
self.ln_pre = LayerNorm(width)
self.transformer = Transformer(width, layers, heads)
self.ln_post = LayerNorm(width)
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def forward(self, x: torch.Tensor):
# 开始时,x = [1, 3, 224, 224]
# shape = [*, width, grid, grid], 将图片分成[32,32]个patch,变成[1,768,7,7]
x = self.conv1(x) #
# shape = [*, width, grid ** 2], 合并高宽 [1,768,49]
x = x.reshape(x.shape[0], x.shape[1], -1)
# shape = [*, grid ** 2, width], 更换位置 [1,49,768]
x = x.permute(0, 2, 1)
# shape = [*, grid ** 2 + 1, width], 添加classToken信息,变为[1,50,768]
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1)
# 增加位置信息
x = x + self.positional_embedding.to(x.dtype)
x = self.ln_pre(x)
# NLD -> LND, 从[1,50,768]得到[50,1,768]
x = x.permute(1, 0, 2)
# 多头transformer,,增加注意力信息,矩阵不变得到x [50,1,768]
x = self.transformer(x)
# LND -> NLD, 从[50,1,768]得到[1,50,768]
x = x.permute(1, 0, 2)
# x[:, 0, :] 将所有信息汇聚到cls token中,只需前面来做下游任务 [1,768]
x = self.ln_post(x[:, 0, :])
# self.proj是可学习参数,维度为[768,512]
if self.proj is not None:
# 通过学习参数将维度再次融合变成512特征,最终为[1,512]
x = x @ self.proj
return x
3 text encode 代码
CLIP主函数部分如下
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
# 增加位置信息
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
# 多头transformer,增加注意力信息,矩阵不变
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
4 forward 代码
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
# 特征相乘获得相似度
logits_per_image = logit_scale * image_features @ text_features.t()
# 变成文本
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text
八 小结
经过了解,现在有一些开源相册项目,也已使用CLIP提供搜索功能,比如immichd的智能搜索。
Smart search is powered by the pgvecto.rs extension, utilizing machine learning models like CLIP to provide relevant search results. This allows for freeform searches without requiring specific keywords in the image or video metadata.
有其他开发者也对CLIP的神奇感到了惊讶,比如这个博客I accidentally built a meme search engine介绍的,只有10个小时就简单实现了图像搜索引擎。
I can’t imagine the amount of work we would have done in 2015 to build this. I spent maybe 10 hours total on this and it was trivial.
The results are akin to magic.
噫吁嚱,不得不感叹多模态技术的强大!
针对本文的图像搜索,也可以拓展更多的功能。比如添加备注文本信息、获取图像文件中的GPS信息等提供filter功能。
参考引用
- 向量数据库https://guangzhengli.com/blog/zh/vector-database/
- 向量数据库技术鉴赏(上)https://www.bilibili.com/video/BV11a4y1c7SW
- 向量数据库技术鉴赏(下)https://www.bilibili.com/video/BV1BM4y177Dk
- Chroma https://docs.trychroma.com/getting-started
- QDrant https://qdrant.tech/documentation/quick-start/
- HNSW for Vector Search Explained and Implemented with Faiss (Python) https://www.youtube.com/watch?v=QvKMwLjdK-s
- CLIP https://arxiv.org/abs/2103.00020
- Transformer https://arxiv.org/abs/1706.03762
- Vision Transfomer https://arxiv.org/abs/2010.11929
- Transformer讲解https://youtu.be/zxQyTK8quyY?si=SC3EtcxtgnwLuhOV
- Vision Transformer详解 https://blog.csdn.net/qq_37541097/article/details/118242600
- 多模态模型学习1——CLIP对比学习 语言-图像预训练模型 https://blog.csdn.net/weixin_44791964/article/details/129941386
- 多模态表征—CLIP及中文版Chinese-CLIP:理论讲解、代码微调与论文阅读 https://blog.csdn.net/weixin_44362044/article/details/136262247