本文以markdown代码块为例,通过分析ViewV2渲染过程、ObserverV2监听机制,利用降低节点数、平替UI组件等策略,实现了内存99%的下降。
一、开篇引语
本文介绍了ima鸿蒙版markdown场景的一些内存优化手段:以markdown代码块的渲染为例,看完之后你将知道:
● 看似用于性能优化的 @observerV2、@trace 注解,为何会反向导致内存飙升?
● @trace的属性最好不超过几个,不然内存可能会翻倍(答案是5个,但为什么呢)?
● 高频出现的 updateFuncByElmtId 到底是个啥,为何成为内存占用 TOP 1 “元凶”?
● 代码块的多字体样式渲染中, Span 组件的滥用会引发严重的内存碎片化。有什么平替方案?
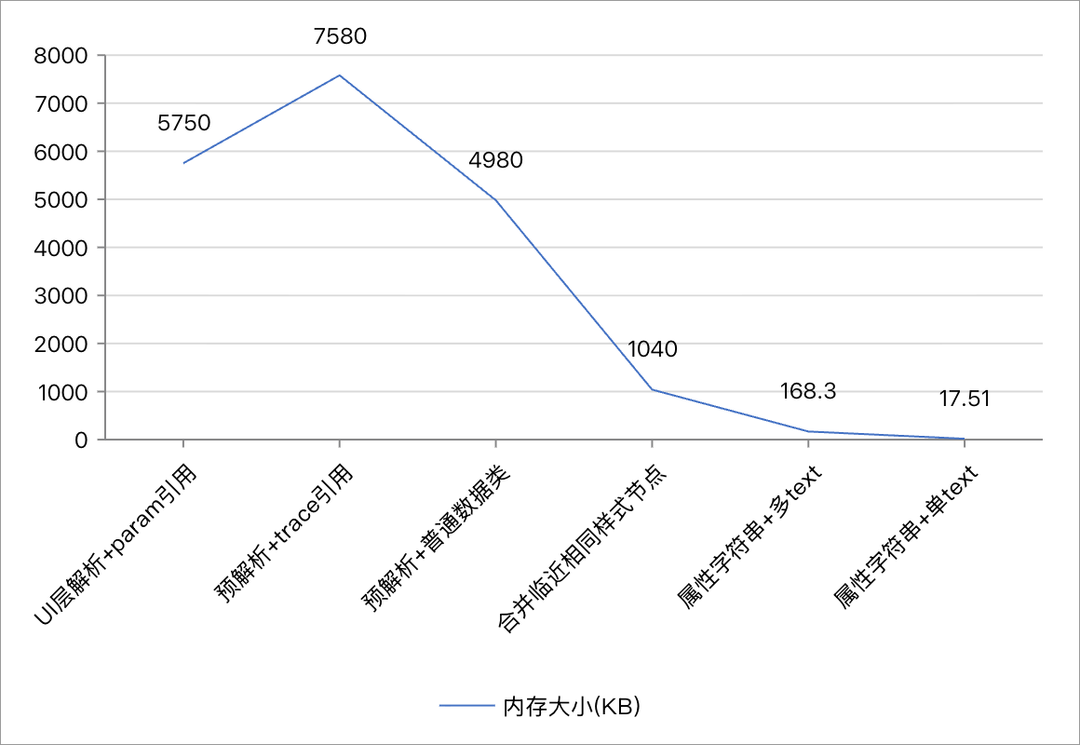
本文将以鸿蒙 ima 应用的代码块渲染为切入点,拆解一场惊心动魄的内存瘦身战:从初始 5MB 的臃肿占用,历经 7MB 的意外膨胀,到1MB的惊喜效果,最终实现了 0.02MB 的极致轻量化。99.7% 的降幅背后,是对鸿蒙底层机制的深度洞察与实战优化。更关键的是,这场优化全程保持滑动性能无劣化,真正做到 “减负不减效”。
二、缘起:从异常的内存数据说起
我们的内存优化征程,始于对开源库 lv-markdown-in(Gitee 链接)的实际测试。
1、异常的__use_refs__:循环引用@Param埋下的内存隐患
通过鸿蒙 DevEco Studio 的内存快照分析,我们在代码块组件的内存详情中发现了诡异现象:排行第三的__use_refs__对象占用 192.48KB 内存,其中 99.8%(192.12KB)都被一个codeTheme的 Set 集合(长度高达4366)占据。
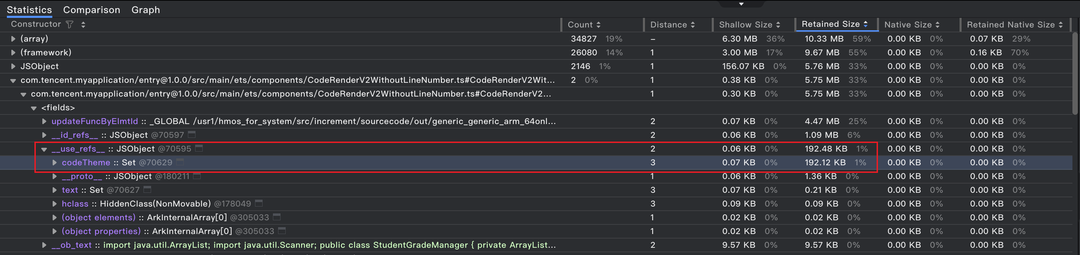
怎么回事儿?这里的codeTheme是个@Param,不是只有一个才对吗?
追溯源码后真相浮出水面:原作者在嵌套的多层循环(外层遍历代码行、内层遍历语法片段)中,直接引用了@Param修饰的codeTheme对象。
简单理解就是ForEach组件每次迭代循环,为Span UI节点重复创建了成千上百的codeTheme的强引用,最终导致 Set 集合无限膨胀。
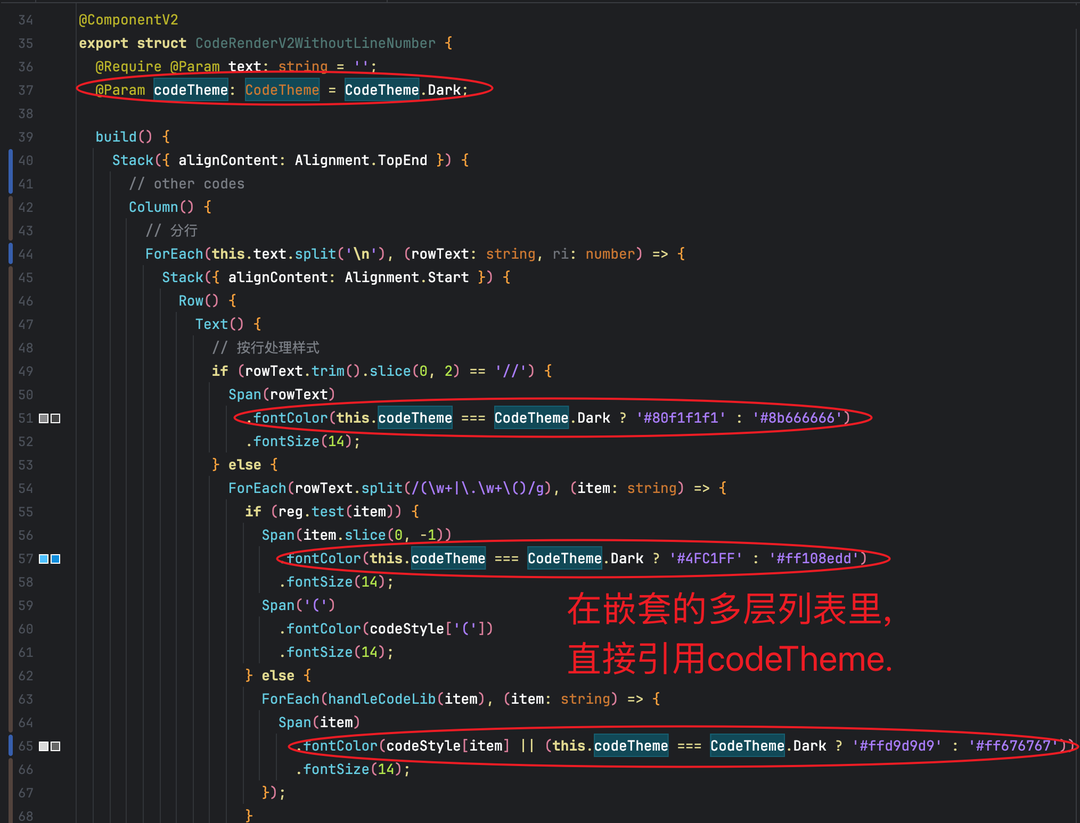
这个时候笔者灵机一动:既然 UI 层直接解析,会因为引用codeTheme而产生大量冗余依赖。那我就将codeTheme的样式解析逻辑,迁移到逻辑层进行预解析,通过@Trace注解追踪预解析后的样式数据。
这既能剥离 UI 层的沉重依赖(UI层、逻辑层解耦合),又能借助状态管理 V2 的精准更新能力提升性能。

2、预解析的悖论:局部优化与整体膨胀的矛盾
按照这个思路重构后,代码结构变为 “逻辑层预解析样式→@Trace标记状态数据→UI 层直接渲染”。
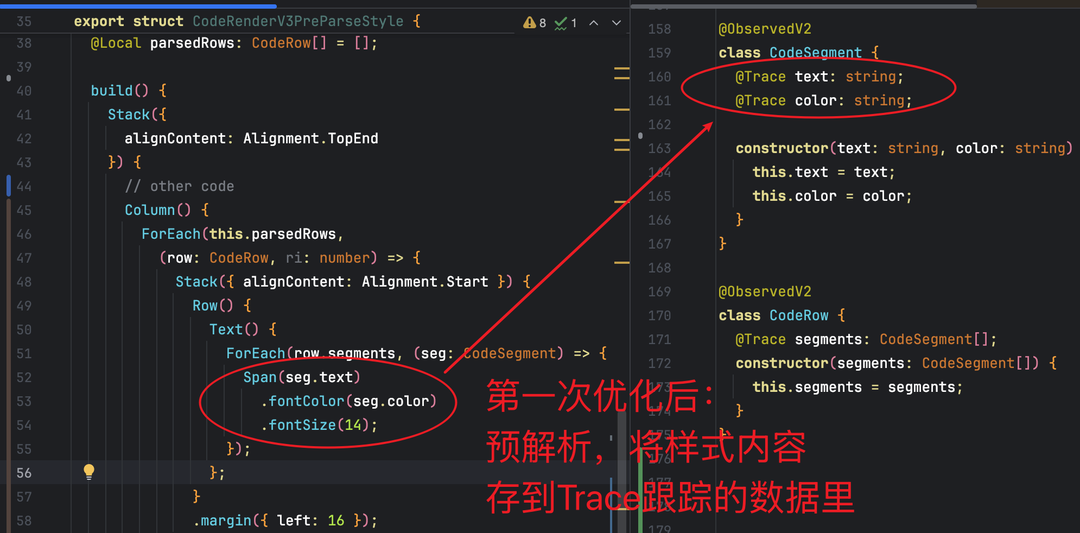
初步看内存快照,局部指标确实迎来了显著优化:当看到__id_refs__和__use_refs__几乎归零的瞬间,笔者一度以为找到了最优解。
| 优化前 | 优化后 | 对比 | |
|---|---|---|---|
| updateFuncByElmtId | 4.47 | 3.43 | 下降23% |
| id_refs | 1.09 | 0.002 | 下降99% |
| use_refs | 0.19 | 0.001 | 下降99% |
| 总内存 | 5.75 | 7.57 | 上升32% |
但总内存从 5.75MB 飙升至 7.58MB 的现实,给了笔者沉重一击:明明剥离了冗余依赖,为何内存反而膨胀了?

3、致命阈值:@Trace 注解的内存爆炸之谜
带着这个悖论,我们启动了控制变量法排查:逐一剥离预解析中的业务逻辑、注释冗余代码,最终所有线索都指向了@Trace注解。
通过固定其他变量、仅调整@Trace修饰的属性数量,我们得到了更令人震惊的数据:
| 内存指标(MB) | 优化前 | 2个@Trace | 12个@Trace |
|---|---|---|---|
| updateFuncByElmtId | 4.47 | 3.43 | 3.43 |
| id_refs | 1.09 | 0.002 | 0.002 |
| use_refs | 0.19 | 0.001 | 0.001 |
| 总内存 | 5.75 | 7.57 | 25.96 |
令人费解的是,这种由@Trace引发的内存增长,在常规的内存快照(Snapshot)中完全无法体现 —— 所有被注解修饰的属性都显示正常占用,仿佛有一部分 “隐形内存” 在鸿蒙的 GC 追踪之外疯狂滋生。

我们已就此现象向华为技术团队提单反馈,截至本文发布仍在等待官方回复。
更诡异的是,当@Trace注解数量从 5 个增加到 6 个时,内存发生了断崖式暴涨 —— 从 7.69MB 直接飙升至 25.73MB,增幅高达 235%!而后续继续增加注解数量,内存继续保持了线性变化
| trace数 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|
| 总内存 (MB) | 7.62 | 7.65 | 7.69 | 25.73 | 25.77 | 25.81 | 25.85 |
开什么玩笑!!!

从循环引用的小异常,到优化变劣化的悖论,再到注解数量的致命阈值,这一系列反常现象背后,必然隐藏着鸿蒙状态管理 ObserverV2 & Trace 的一些底层实现逻辑。
所幸经过探索,笔者已大致明白原因。接下来,我们将结合鸿蒙源码,拆解@Trace注解的实现机制与组件依赖收集的核心原理,揭开这场内存谜题的真相。
三、@trace的内存大在了哪里
1、核心概念:双向追踪的设计本质
官方文档对 V2 装饰器的定义比较简单(官方文档)。经过查看源代码,其底层是一套 “属性 - 组件” 双向追踪体系:
● @ObservedV2:为数据类注入 “可观察能力” 的 “包装器”,仅当类中存在 @Trace 属性时才激活追踪逻辑,嵌套类需每层添加该注解才能实现深度观测。
● @Trace:属性的 “感知探针”,通过重写 getter/setter 实现两大核心功能:
○读操作(getter):记录 “哪个 UI 节点读取了该属性”(依赖收集);
○写操作(setter):通知 “所有依赖该属性的 UI 节点更新”(更新触发)。
● ObserveV2 引擎:追踪中枢,维护依赖栈、弱引用映射表、VSync 驱动的更新队列,是内存消耗的核心载体。
2、编译产物:没有变化?
我们先排查 ArkTS 编译产物(路径举例:entry/build/default/cache/default/default@CompileArkTS/esmodule/debug/entry/src/main/ets ),发现一个关键现象:
UI 组件代码因依赖追踪逻辑发生明显重构;
被 @Trace 修饰的属性定义完全未变,既无额外字段也无代理逻辑。
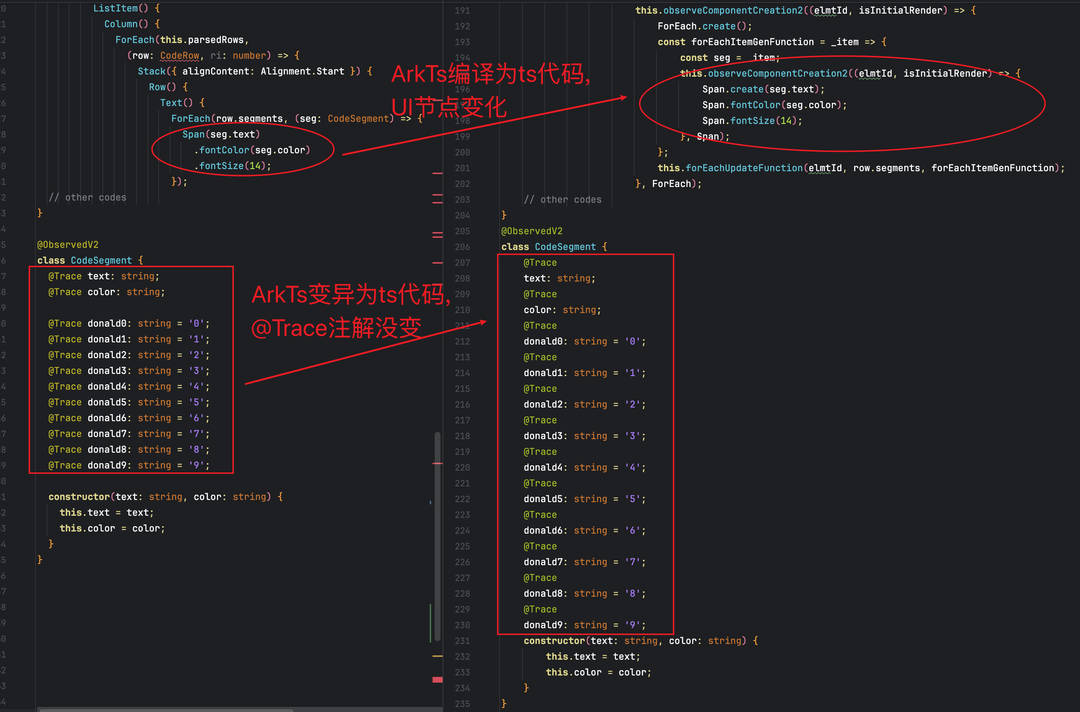
这说明:@Trace 的内存消耗并非来自编译期代码膨胀,而是运行时由 ObserveV2 相关引擎动态生成的数据结构。笔者猜测这可能也是常规内存快照无法捕获 “隐形内存” 的原因?
接下来我们深入鸿蒙源码,揭开这套动态机制的面纱。
3、 源码深析:ObserveV2 的内存枷锁
注意仓库已迁移至gitcode.com/openharmony/arkui_ace_engine, google搜索第一位的gitee码云的仓库已经暂停了。@observerV2的实现在: https://gitcode.com/openharmony/arkui_ace_engine/blob/master/frameworks/bridge/declarative_frontend/state_mgmt/src/lib/v2/v2_change_observation.ts
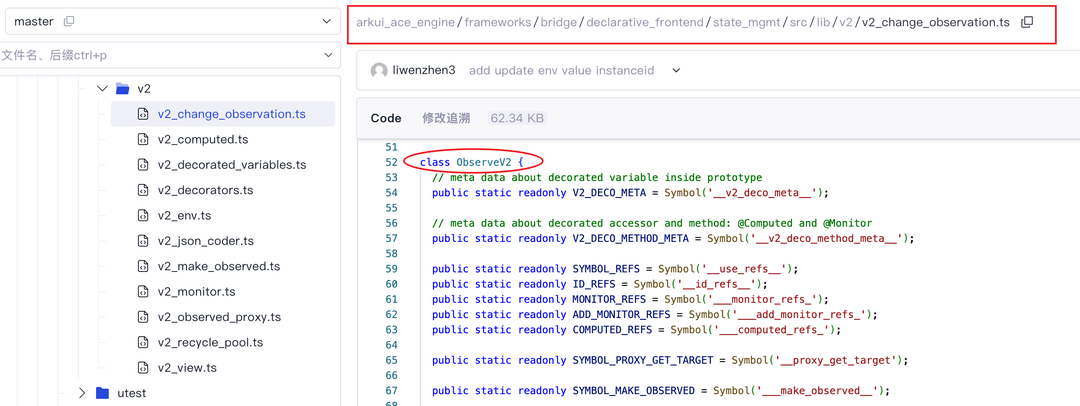
3.1 基础架构:ObserveV2与Trace内存的 “三座大山”
@ObservedV2 与 @Trace 的核心逻辑分散在三个关键文件中,其内存占用从属性初始化阶段就已产生。
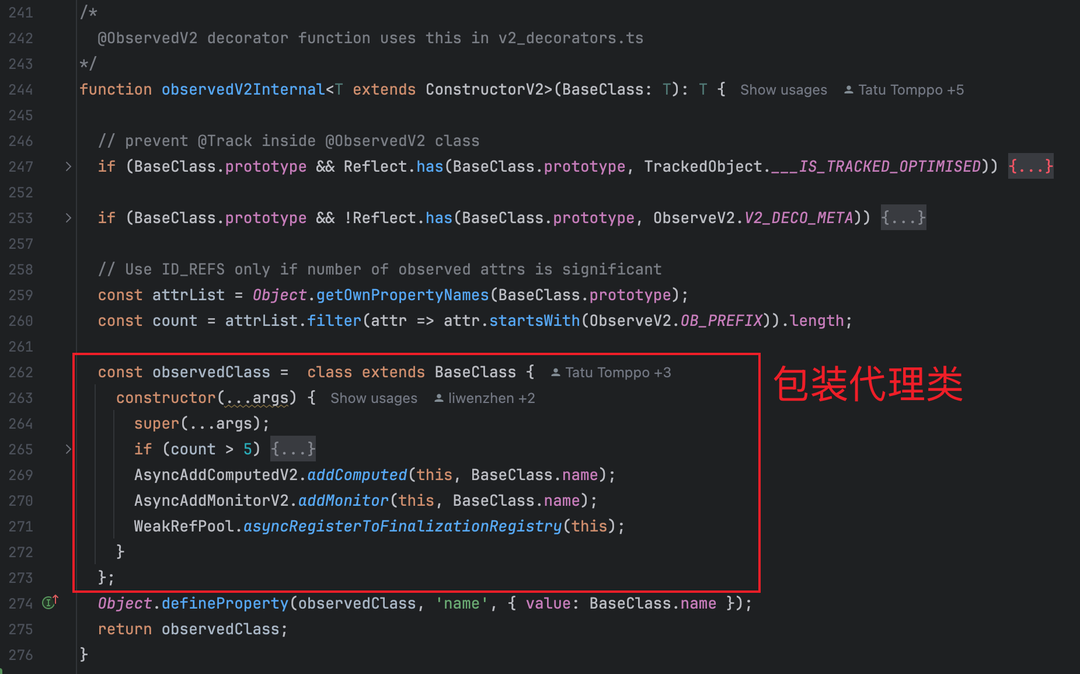
3.1.1 类包装逻辑(v2_decorated_variables.ts:244-276)
@ObservedV2 会为数据类生成一个 “包装代理”,即使未触发属性读写,也会占用基础内存;
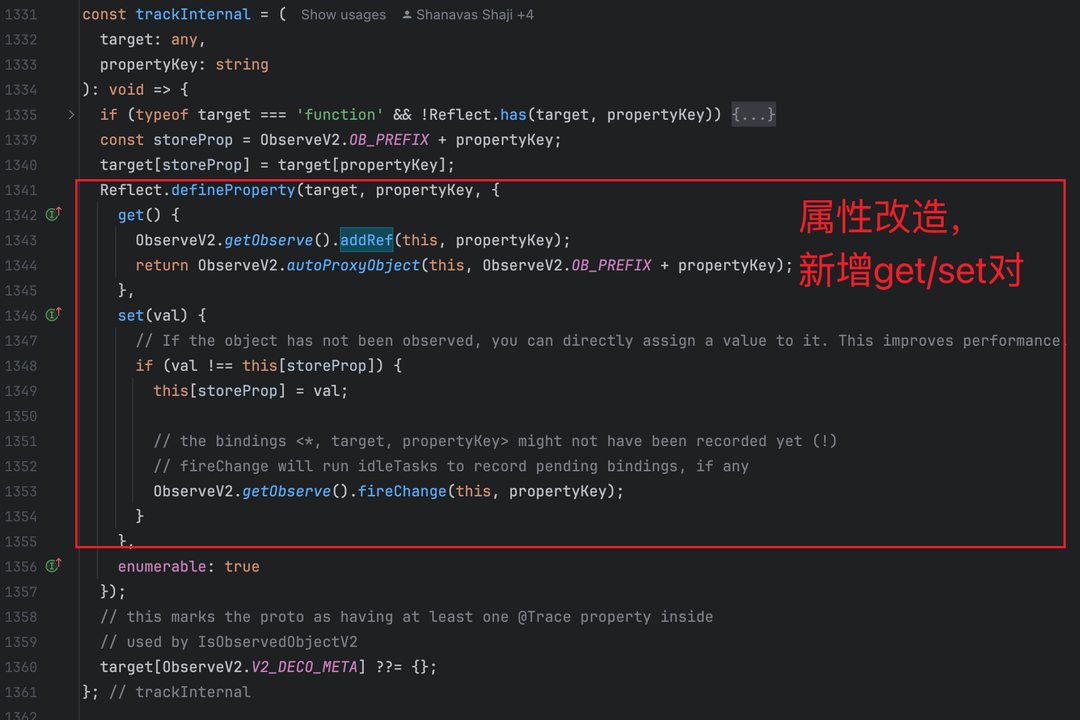
3.1.2 属性改造机制(v2_change_observation.ts:1331-1361)
● @Trace 通过trackInternal函数重写属性,为每个属性创建独立后备存储(命名为__ob_
● 生成带依赖记录的 getter/setter 对:
○ Getter:调用ObserveV2.addRef(this, ‘
○ Setter:值变化时触发ObserveV2.fireChange(this, ‘
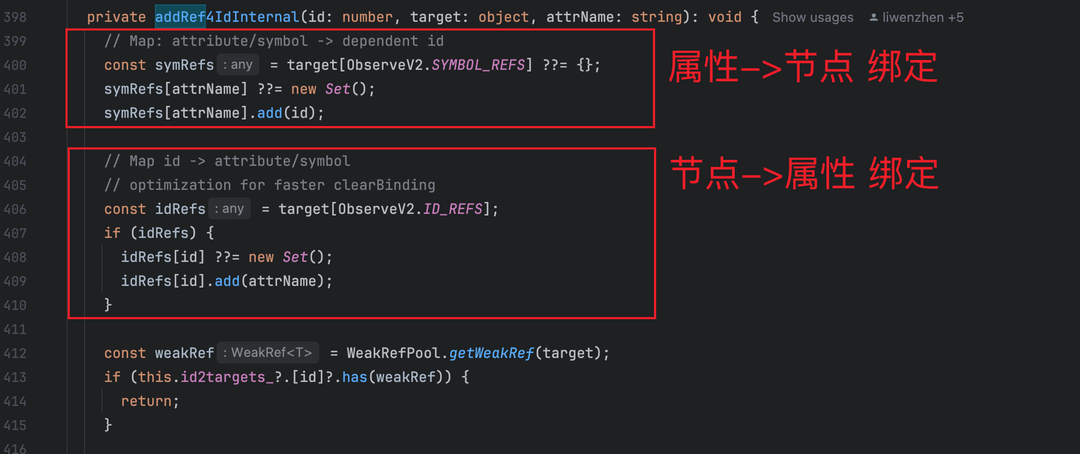
3.1.3 依赖存储结构(v2_change_observation.ts:398-428)
● 框架在可观察对象上维护两个核心集合(基于搜索到的双向映射机制):
○ SYMBOL_REFS:前向映射,key 为属性名,value 为依赖该属性的 UI 节点 elmtId 集合(Set 类型);
○ ID_REFS:反向映射,key 为 elmtId,value 为该节点依赖的属性名集合(Set 类型);
这两个集合形成 “属性 - 节点” 双向绑定,每个绑定关系都会占用额外内存。
3.2 运行时时序:依赖收集的 “滚雪球效应”
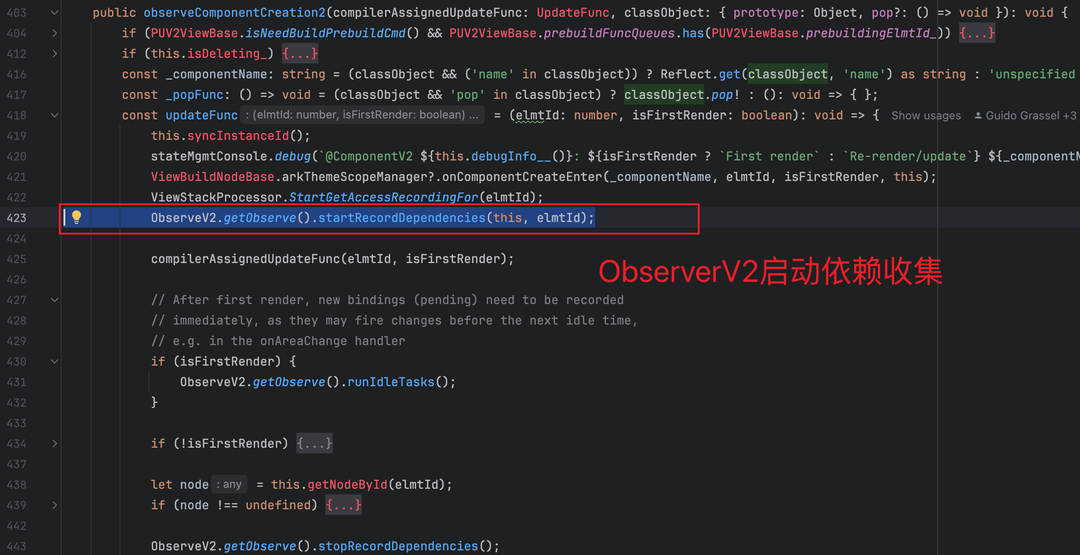
对于3.1的“三座大山”,当组件渲染时,依赖收集的时序逻辑如下,其会进一步放大内存消耗:
● 依赖窗口开启:组件进入更新函数时,observeComponentCreation2(v2_view.ts:423-445)调用ObserveV2.startRecordDependencies,标记当前渲染周期为 “依赖收集窗口”。
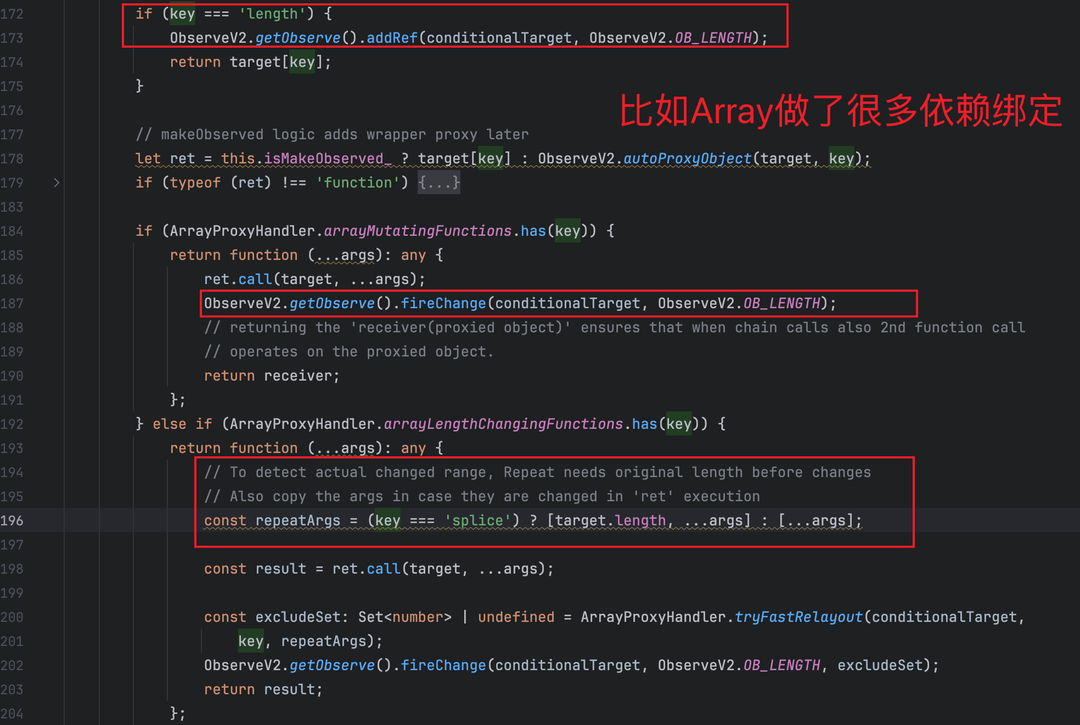
● 属性读取触发记录:UI 层读取 @Trace 属性时,addRef会将 “当前 elmtId→属性名” 同时写入SYMBOL_REFS和ID_REFS(若启用反向索引)。
● 集合代理叠加:若属性为 Array/Set/Map 等集合类型,getter 会生成代理对象(v2_observed_proxy.ts),为数组 length、Map 键值等附加新的依赖记录。例如:
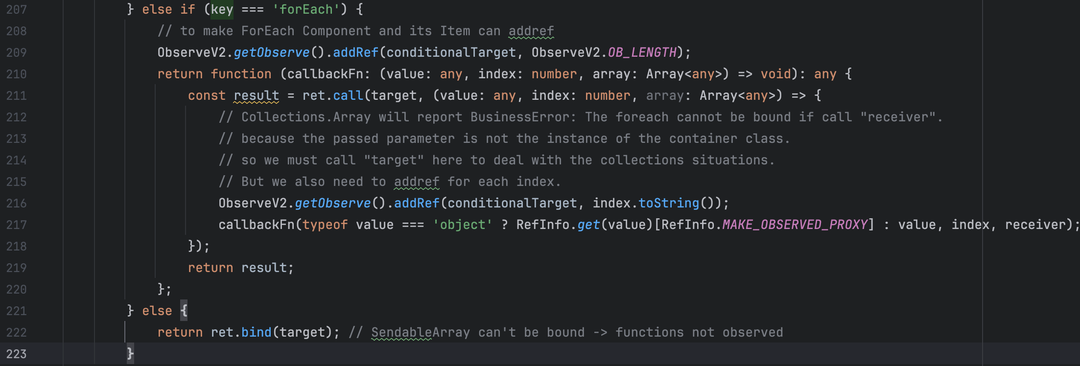
● 数组forEach遍历会为每个索引创建OB_LENGTH依赖引用。
4、内存新增:多层 ForEach 下的 “乘积效应”
结合代码块渲染的实际场景(多层 ForEach 遍历代码行→语法片段→文本属性),@Trace 的内存增长呈现 **“属性数 × 节点数 × 层数” 的三维乘积效应 **,具体拆解如下:
4.1 基础内存构成(单属性)
每个被读取的 @Trace 属性,内存占用包括三部分:
● 后备存储__ob_
● 属性描述符(getter/setter)。
● SYMBOL_REFS集合条目,会再倍乘elmtId 数量。
4.2多层循环的 “放大因子”
笔者自测,目标case代码块渲染的多层 ForEach(193 行代码 ×每行拆分的语法片段)会产生 4949 个 UI 节点,若每个节点读取 3个 @Trace 属性,再叠加集合代理(如数组 segments 的索引依赖,有个@trace的array)最终多生成(49493+1931)*N个动态内存单元,内存上新增的单元轻轻松松多了上万个。
5、破局方案:按需剥离追踪能力
针对上述机制,我们采用 “非动态数据去追踪化” 方案:将原 @ObservedV2 修饰的类改为普通 interface,彻底切断双向追踪链路。
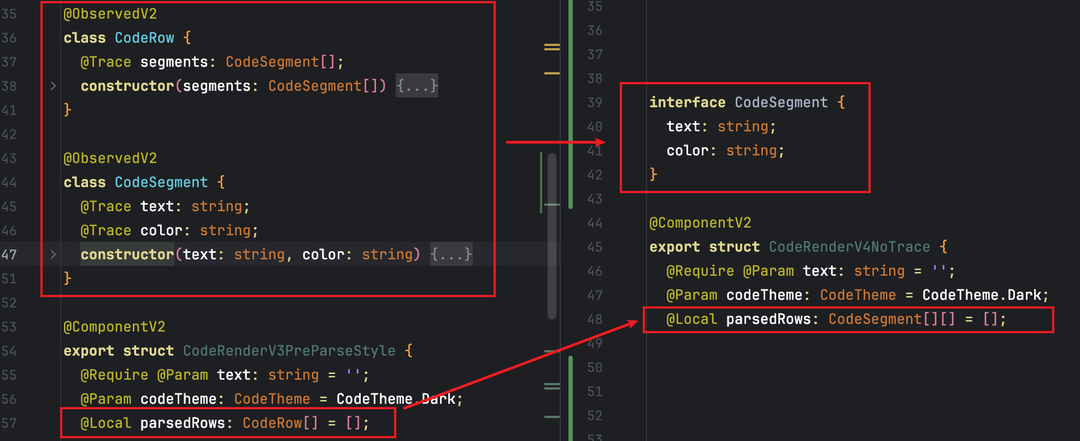
5.1 改造前后内存对比
可以看到总内存直接降下来了,内存降幅高达35%。
| ObserverV2+trace | interface | |
|---|---|---|
| 总内存 | 7580 | 4980 |
| updateFuncByElmtId | 3.43 | 3.43 |
| id_refs | 0.002 | 0.002 |
| use_refs | 0.001 | 0.001 |
5.2 原理解析
interface 之所以能大幅降内存,核心在于三点:
● 无运行时包装:interface 仅为类型声明,不会生成 @ObservedV2 的代理对象;
● 无后备存储:属性直接读写,无需__ob_
● 无依赖集合:不触发addRef与fireChange,SYMBOL_REFS和ID_REFS无新增条目。
5.3 适用场景
该方案仅适用于静态数据场景:代码块渲染中,预解析后的样式数据不会动态变化,无需 @Trace 的追踪能力。若需处理动态数据,可采用 “核心属性保留追踪,非核心属性剥离” 的折中方案。

四、从五到六:@Trace 内存爆炸的阈值谜题
在内存测试中,最令人费解的现象莫过于:当 @Trace 注解数量从 5 个增至 6 个时,总内存从 7.69MB 飙升至 25.73MB,增幅高达 235%。
我们进一步把JSObject的数量统计了出来,用于量化分析对比。主要发现是JSObj新增了4951个(23637-18676=4951)。
| trace数量 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|
| 总内存(MB) | 7.62 | 7.65 | 7.69 | 25.73 | 25.77 | 25.81 | 25.85 |
| JSObj数量 | 18672 | 18674 | 18676 | 23627 | 23629 | 23631 | 23633 |
| JSObj内存 | 13.14 | 13.14 | 13.14 | 31.11 | 31.11 | 31.11 | 31.11 |
1、 阈值触发的底层逻辑
1.1 阈值触发的底层逻辑
鸿蒙框架在v2_decorated_variables.ts的observedV2Internal函数中(第 258-268 行),暗藏着一段关键的计数逻辑:
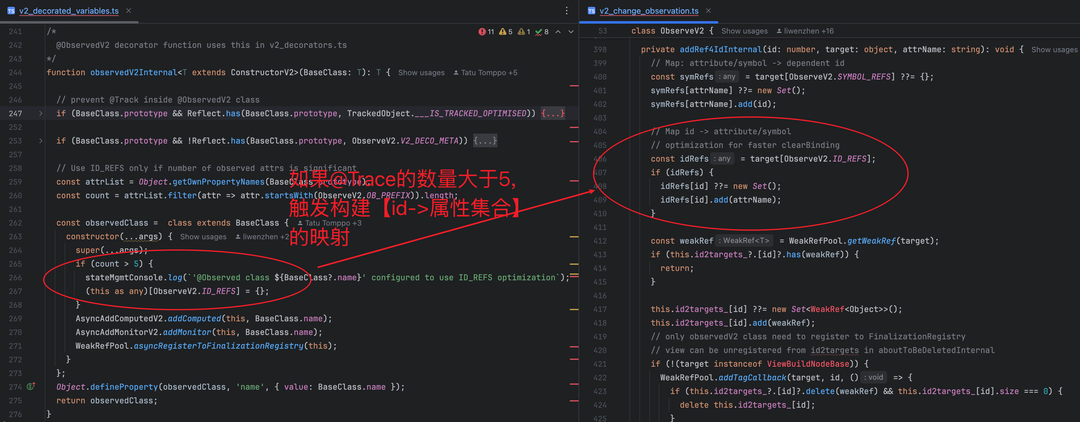
这段代码的核心逻辑是:通过统计类原型上以__ob_为前缀的属性(每个 @Trace 属性都会生成对应的后备存储__ob_
1.2 框架的 “优化初衷”
框架设计这个阈值的本意,是基于 “属性数量 - 清理效率” 的权衡。在v2_change_observation.ts:236-248,可以看到:
● ≤5 个 @Trace 属性:组件销毁时清理依赖,只需遍历所有属性的SYMBOL_REFS集合(前向映射),逐个移除当前组件 id 即可。由于属性少,遍历成本极低;
● >5 个 @Trace 属性:遍历多个属性集合的成本上升,因此启用 ID_REFS 反向索引 —— 通过 “组件 id→属性名集合” 的映射,clearBinding(id)时可直接定位该组件依赖的所有属性,无需遍历全部属性。
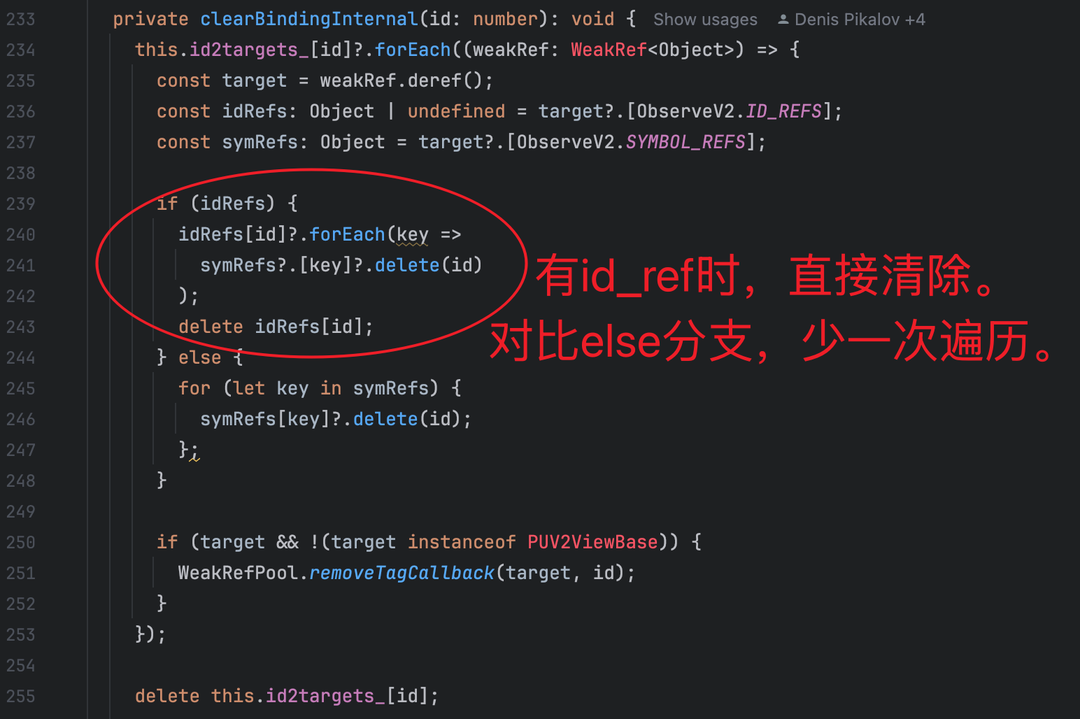
设计初衷我们知道了,但是这会带来什么代价呢?

笔者认为,框架忽略了一种极端场景:当属性数刚超阈值,且依赖该数据的 UI 节点数量极大时(如多层 ForEach 生成数千个节点),反向索引的内存开销会瞬间超过清理效率的收益。
2、 反向索引的 “隐形内存炸弹”:开销构成拆解
ID_REFS 的启用,相当于在原有内存结构上 “复制” 了一套规模相当的依赖存储体系。接下来我们结合代码块的业务场景,实际分析下其开销构成:
2.1 双集合写入的基础开销
启用 ID_REFS 后,ObserveV2.addRef函数(v2_change_observation.ts:406-410)会执行 “双集合写入”:
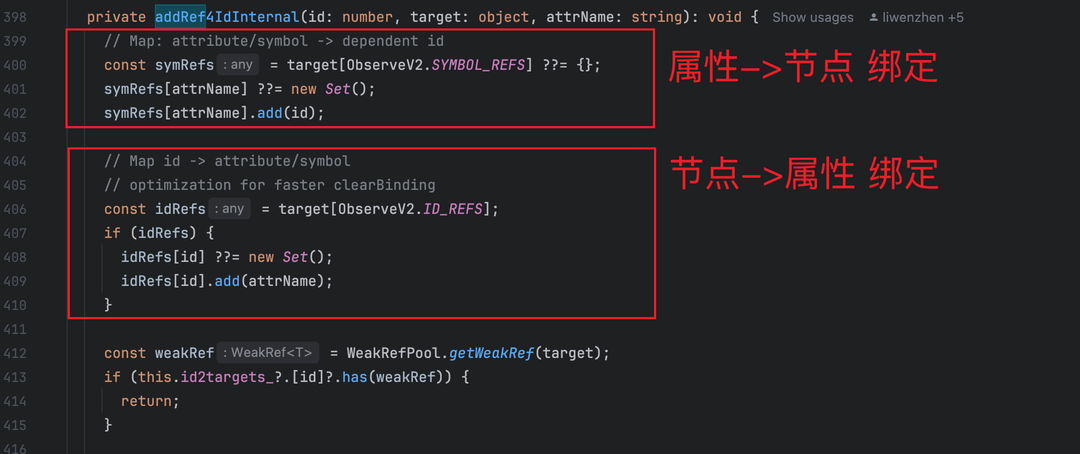
这段代码暴露了核心开销:每个 UI 节点首次读取属性时,会新增一个 Set 对象(存储该节点依赖的属性名)。在我们的场景中,引用ObservedV2对象的 UI 节点数量达 4949 个,这意味着仅反向集合的 Set 对象就新增近 5000 个。
2.2 数量级倒挂的放大效应
反向索引的开销与 “UI 节点数” 和 “属性数” 的比例强相关:
● 当UI 节点数(id 基数)>>属性数时(如我们的场景:4949 个节点 vs 12 个属性),反向集合的条目数(节点数 × 平均依赖属性数)会远超前向集合(属性数 × 平均依赖节点数);
● 典型场景计算(基于实测数据):
○ 前向集合:12 个属性 × 平均 4949 个节点 = 59,388 个条目;
○ 反向集合:4949 个节点 × 平均 2 个依赖属性 = 9,898 个条目;
虽然条目数更少,但反向集合新增了 4949 个独立 Set 对象 —— 每个 Set 的基础内存开销3.5KB(后续会介绍约 3.5KB,含对象头、哈希表结构)远高于单个条目。
最终,这种 前向集合+反向集合 “你引用我,我引用你”的逻辑,导致了内存暴涨。

2.3 JSObject 的批量生成量化拆解
结合内存快照数据,反向索引启用后新增的 4951 个 JSObject(从 18676 增至 23627),其构成可精确对应:
● 4949 个:ID_REFS 中为每个 UI 节点创建的Set
● 2 个:每新增一个trace,本身就会线性新增2个JSObject。笔者推测是新增第 6 个 @Trace 属性对应的后备存储__ob_
这与 “4949 + 2 = 4951” 的实测数据完全吻合,印证了开销构成的分析。
3、数据印证:内存爆炸的量化解析
3.1 核心数据对应表
将源码机制与实测数据结合,可清晰还原 “从 5 到 6” 的内存暴涨过程:
| 指标 | 5个@Trace | 6个@Trace | 增量 | 解释 |
|---|---|---|---|---|
| 总内存 | 7.69MB | 25.73MB | +18.04MB | 反向集合 + 新增 JSObject |
| JSObj数量 | 18676个 | 23627个 | +4951个 | 4949 个 Set + 2 个属性对象 |
| JSObj内存 | 13.14MB | 31.11MB | +17.97MB | Set 对象基础开销 + 条目存储 |
因此,我们大胆推测 18000KB / 4951个 约为 3.6KB/个,推测trace数量从5到6时,新增大量3.6KB左右的JSObject。
3.2 内存暴涨原因的验证
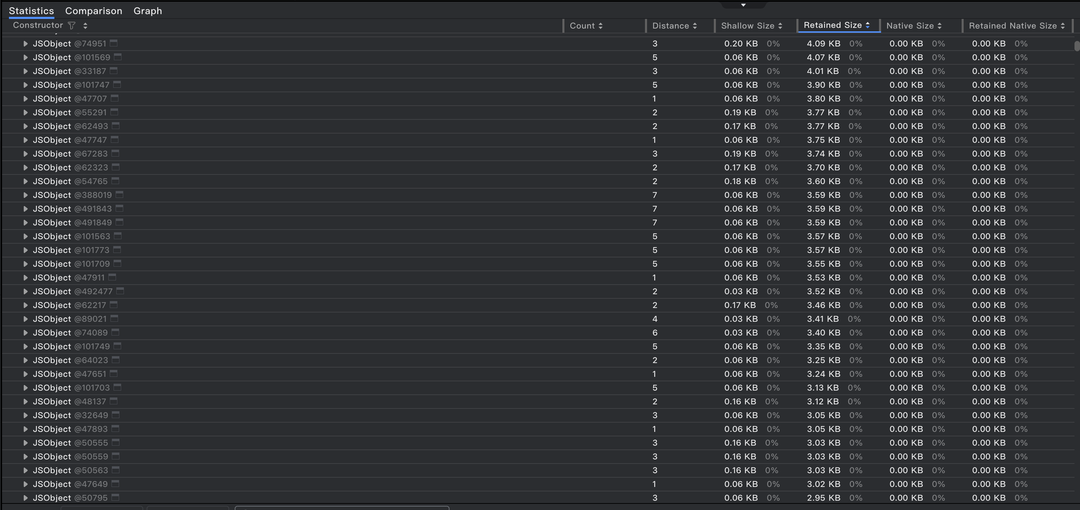
这是@Trace属性数量为5时,可以看到3.6KB左右的JSObject很少。
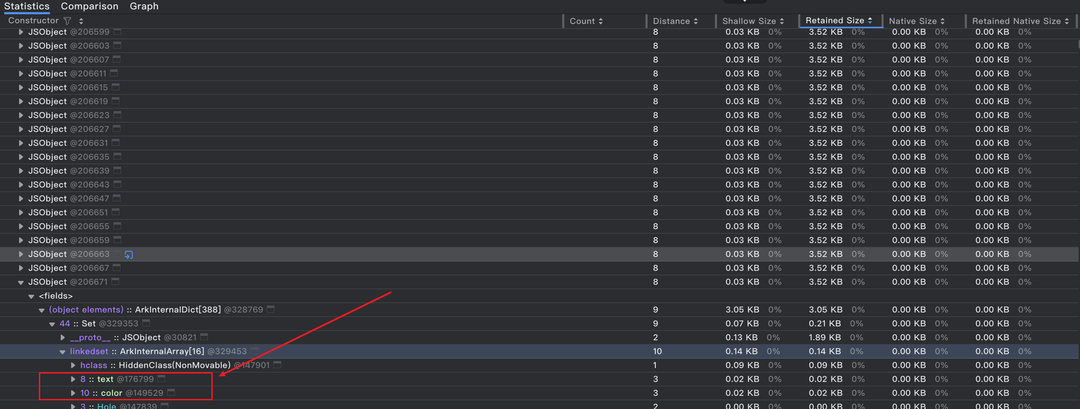
这是**@Trace属性数量为6时,可以看到大量内存大小为3.52KB的JSObejct**。
新增了大量3.52KB的JSObject,且JSObject内容里出现了 text、color这些@Trace属性字样。3.52KB * 4949 = 17.42MB,接近代码块UI节点的内存总增量18MB(误差推测来自不同 Set 的条目数量差异)。
说明这里的量化解析正确。
3.3 阈值后的稳定期原因
当 @Trace 数量从 6 增至 9 时,内存仅从 25.73MB 增至 25.85MB,增长趋于停滞:
原因是 ID_REFS 已在 6 个属性时完全启用,后续新增属性仅需:
● 为该属性创建后备存储和描述符。
● 在已有 Set 集合中添加条目(但由于新增的trace没使用到,实际不用新增)。
无新增 Set 对象,因此内存增长微乎其微。
4、本质总结:设计权衡的场景失效
笔者认为:@Trace 数量 “从 5 到 6” 的内存爆炸,本质是鸿蒙框架的 “属性数驱动优化” 与 “节点数主导场景” 的冲突 :
● 框架的设计假设:属性数是影响清理效率的核心变量;
● 业务场景的颠覆:在多层 ForEach 中,UI 节点数才是决定内存开销的关键;
● 矛盾结果:为优化 “多属性清理效率” 而启用的反向索引,反而因 “多节点场景” 产生了海量冗余 Set 对象,最终引爆内存。
这一现象就**需要开发者在使用 @ObservedV2/@Trace 时,必须结合数据规模与渲染场景进行 “阈值预判”**了。
● 当 forEach 场景 UI 节点数超过千级时,如果@Trace属性数超过 5 个,可能触发内存灾难。
● 如果 UI 节点数较少,就不用care类里@Trace的属性数。
五、占大头的 updateFuncByElmtId 是个啥
trace的问题解决了,内存经历了5.75MB->7.58MB->4.98MB的变化。此时的内存占比成了这样。updateFuncByElmtId展开后,内部map的size是5635。

可以看到只剩updateFuncByElmtId这个大头了。那这个究竟是什么呢?

1、核心定位
updateFuncByElmtId本质是个map。它是 ViewV2 维护的 “元素 ID(elmtId)→ 更新函数记录” 映射索引,核心作用是将 ArkUI 组件实例与对应的渲染 / 更新逻辑建立稳定关联。每个组件在创建时都会分配唯一 elmtId,并通过该索引快速定位其更新所需的全部资源。
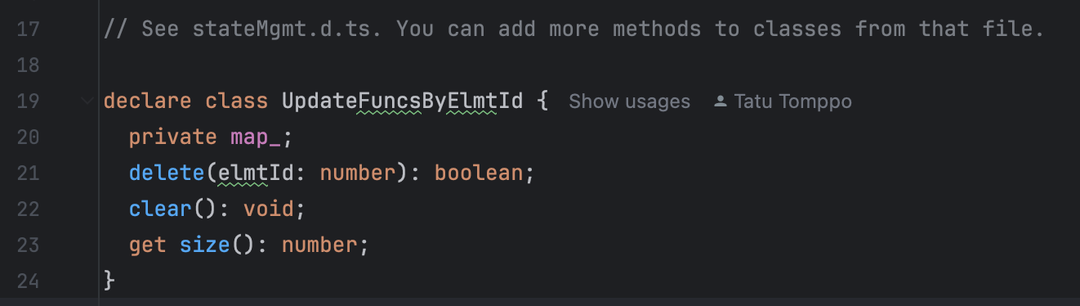
2、 生产流程: updateFuncByElmtId是如何创建的
updateFuncByElmtId的映射关系在组件生命周期的关键阶段建立,核心分为初次渲染和预构建两种场景。这里主要以初次渲染为例,讲解一下:
● 触发创建:ViewV2子组件触发创建节点。
● 动态创建更新函数:编译器生成组件的更新函数,并包装为updateFunc闭包。
● 生成elemId: ViewV2通过ViewStackProcessor.AllocateNewElmetIdForNextComponent为组件分配唯一 elmtId。
● 建立映射关系:将 elmtId 与{updateFunc, classObject}存入updateFuncByElmtId。
● 记录归属关系:通过UINodeRegisterProxy保存 “elmtId→所属视图” 的弱引用,为后续清理做准备。
● 依赖记录与首次渲染:调用ObserveV2.startRecordDependencies执行首次渲染并记录状态依赖,首帧结束后通过ObserveV2.runIdleTasks处理潜在的即时变更绑定。
源代码大致如下(左侧是笔者自己写的组件demo;右侧是ViewV2源代码):
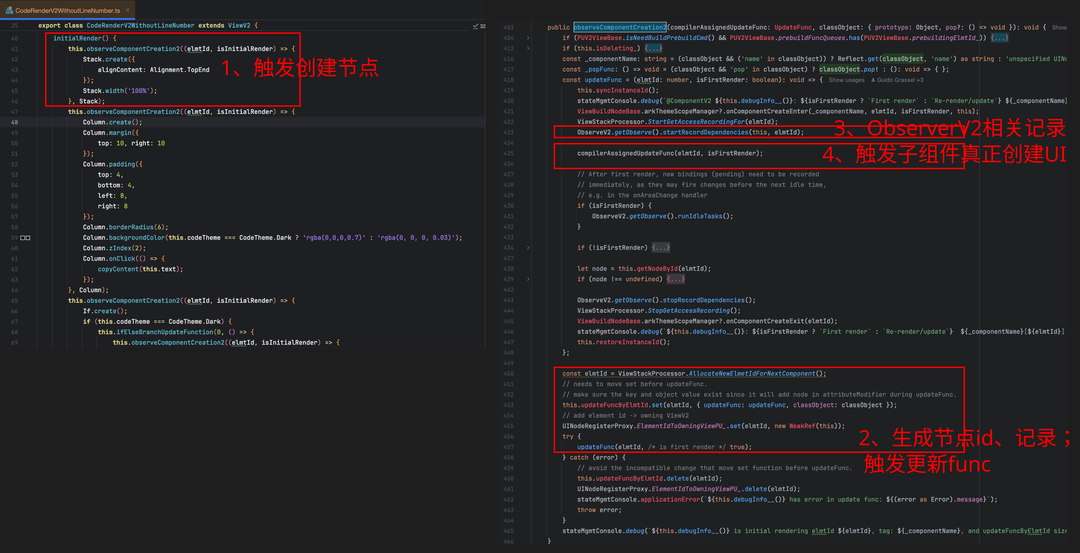
时序图大致如下:其中
● 绿色部分:ViewV2创建updateFuncByElmtId并记录。
● 红色部分:ViewV2调用子组件(也就是鸿蒙开发的业务代码)的节点创建。
● 黄色部分:进行OvserverV2相关的依赖记录等。
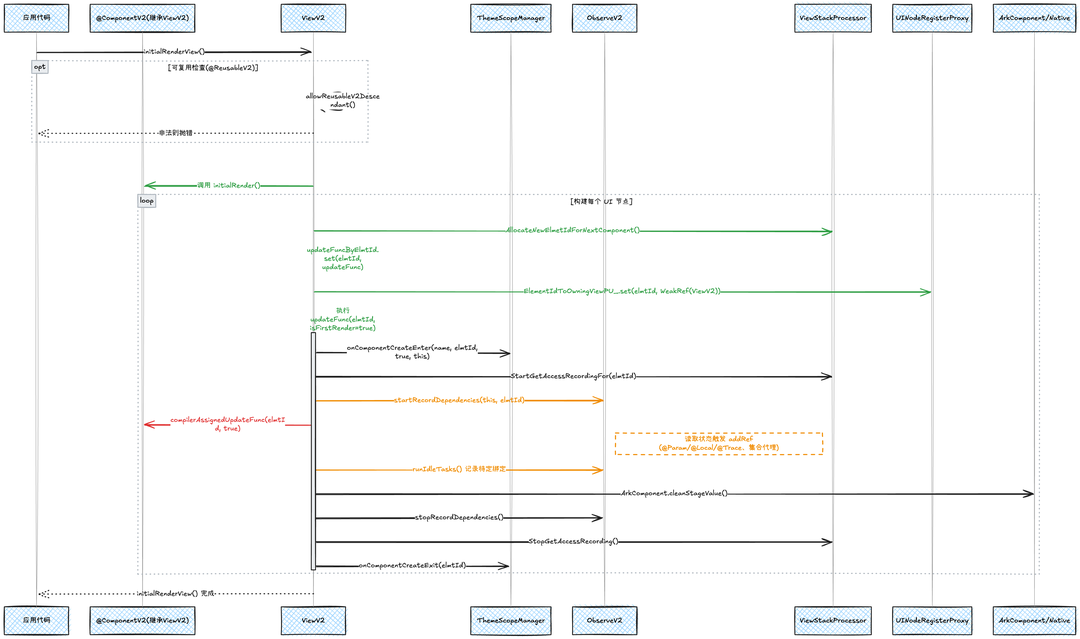
3、核心作用机理:从标记到更新的完整链路
updateFuncByElmtId作为更新流程的 “路由核心”,贯穿了 “标记更新 - 执行更新 - 删除清理” 的全生命周期,确保增量更新的精准性和高效性。
3.1. 标记更新:精准定位受影响组件
当@Trace装饰的状态属性发生变化(V2 支持深层嵌套属性精准监听),ViewV2 会调用uiNodeNeedUpdateV2(elmtId)将目标组件加入 “脏队列”,并在视图处于活跃状态时触发更新。
这一步依托ObserveV2的依赖记录能力,实现 “状态变化→组件定位” 的精准映射。
3.2. 执行更新:有序且最小化的渲染
● 更新排序:脏队列中的组件按 elmtId 升序排列执行更新,确保 “父节点先更新、子节点后更新”,避免子节点依赖的父结构已变更导致的渲染异常;
● 核心执行:通过UpdateElement(elmtId)完成实际更新 —— 从updateFuncByElmtId中取出对应的UpdateFuncRecord,处理pending/changed状态位,执行updateFunc,最后调用原生侧finishUpdateFunc(elmtId)完成增量更新;
● 节点复用:借助UpdateFuncRecord中保存的node引用,通过createOrGetNode()复用已存在的原生节点,避免重复创建节点带来的性能开销。
3.3. 删除清理:确保索引与状态一致
● 原生侧触发:组件在原生侧被删除后,其 elmtId 会转移到UINodeRegisterProxy。
● JS 侧同步:UINodeRegisterProxy统一下发删除通知,各 View 从updateFuncByElmtId中清除对应映射。
● 深度清理:ViewV2.purgeDeleteElmtId会递归标记子视图删除、解除依赖绑定,彻底清理状态与索引,防止对已删除组件执行无效更新。
4、破局方案:减少UI节点,降低updateFuncByElmtId记录数
在 ArkUI ViewV2 架构中,updateFuncByElmtId作为 “组件 ID - 更新函数 - 原生节点” 的强绑定索引,是增量更新的核心,但也意味着UI 节点数量与它的内存占用、更新开销直接正相关。
4.1 优化思路,减少节点数量
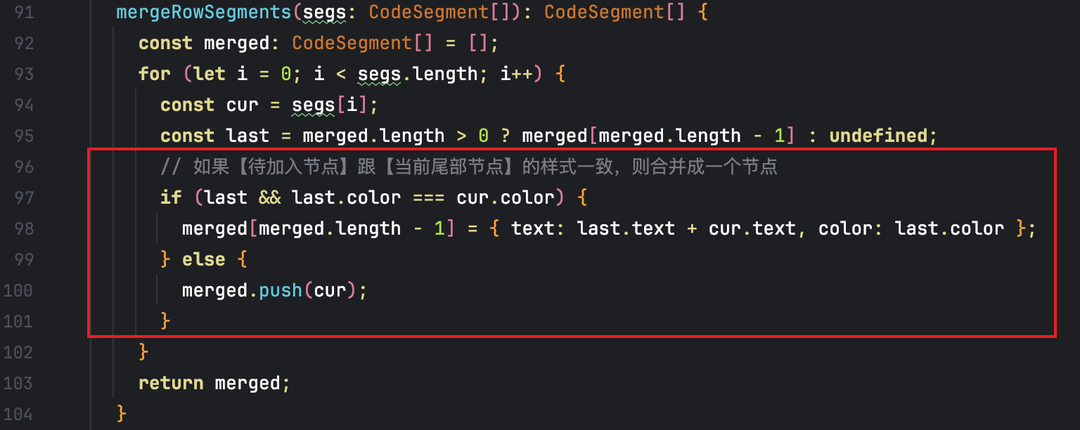
处于内存优化的目的,我们从“减少 UI 节点即优化updateFuncByElmtId,最终实现内存下降” 的核心逻辑出发,主要做了相似样式节点合并:避免重复创建的逻辑**。**
代码高亮场景中,大量连续的 Span 节点往往具有完全相同的样式(如相同的颜色)—— 这些节点的更新逻辑完全一致,没必要单独维护多个 UI 节点和updateFuncByElmtId记录。
笔者在在构建高亮节点分词时,新增 “尾部节点分词样式校验” 逻辑。
● 若样式完全一致,则直接将待加入节点分词的文本内容合并到尾部节点,不创建新的 UI 节点。
● 若样式不同,才创建新节点并加入队列。
4.2优化效果验证:数据见证性能飞跃
经过测试,合并节点后内存占用如下:
| 维度 | 优化前 | 优化后 | 优化幅度 |
|---|---|---|---|
| 高亮代码分词数 | 4949 | 1025 | 下降79% |
| updateFuncByElmtd 记录数 | 5635 | 1325 | 下降76% |
| 整体内存占用 | 4980KB | 1040KB | 下降79% |
此外还有布局性能提升的隐形收益:节点数量减少后,布局阶段的 Measure、Layout 计算耗时降低,页面渲染首帧时间将加快。
六、因地制宜,再破性能天花板
在 ViewV2 架构的内存优化之路上,我们通过合并相似 Span 节点,已将代码高亮场景的内存从 5.75MB 降至 1.04MB,实现了 82% 的优化。
优化到此,似乎已经可以结束了(笔者当时都准备好写KM了)。

但是从减少updateFuncByElmtId的角度出发,有没有更好的方案呢?
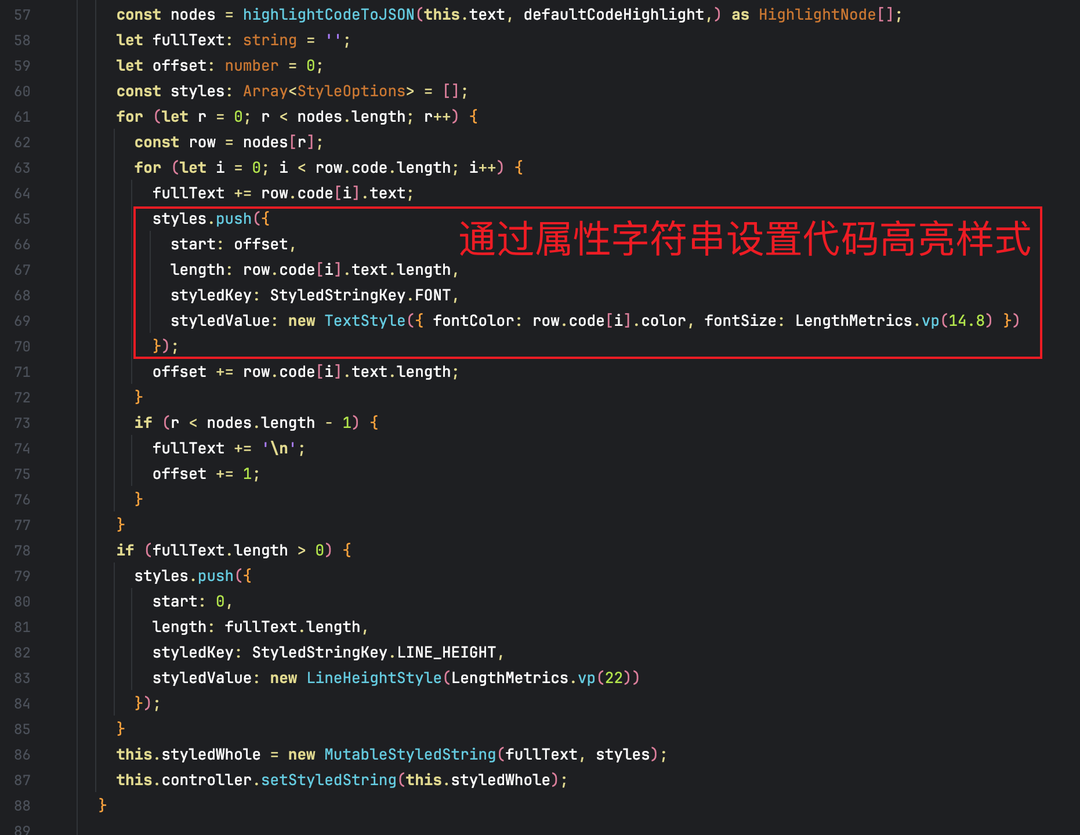
1、 核心发现:属性字符串的写法不需要显示写节点?
在查看属性字符串的文档(StyledString/MutableStyledString,属性字符串)时,笔者发现其不用像Span那样,需要开发者显示创建很多的节点。而是通过TextController创建更新文字样式的。那它的updateFuncByElmtId多吗?
调研发现,属性字符串是鸿蒙提供的高性能富文本解决方案,其设计初衷就是在不增加节点开销的前提下实现灵活样式控制。笔者实际测试发现其不会有额外的节点开销、
updateFuncByElmtId没有暴增。
2、优化策略:属性字符串的落地实践
3、优化效果:从 “优秀” 到 “极致” 的跨越
经过两种方案的实测,核心指标呈现出颠覆性提升,具体对比如下:
| 维度 | 优化前 | 属性字符串 (每行一个text) | 属性字符串 (整体一个text) |
|---|---|---|---|
| updateFuncByElmtId 记录数 | 1325 | 106 | 8 |
| 整体内存占用 | 1040KB | 168.3KB | 17.5KB |
值得关注的是:终极方案的 17.5KB 内存,已无限接近 “无高亮纯 Text 渲染” 的 14.1KB,基本实现了 “高性能高亮 = 无高亮内存” 的理想状态。

回顾总结一下:
之前的优化思路始终围绕 “减少 Span 节点数量”,但 Span 的底层逻辑决定了 “一块分词样式片段 = 一个 UI 节点”—— 即便合并相似节点,仍会残留大量独立节点,每个节点都对应一条updateFuncByElmtId记录。
而属性字符串彻底颠覆了这种模式。
● 它无需创建多个 UI 节点,而是通过TextController将 “文本内容 + 多段样式” 打包绑定到单个 Text 组件上;
● 样式信息以 “字符范围 + 样式配置” 的元数据形式存储,而非通过独立节点承载;
● 无论文本内部有多少种样式差异,最终仅生成与 Text 组件对应的少量 UI 节点,updateFuncByElmtId记录数也随之锐减。
引申一下来讲,在鸿蒙 ViewV2 架构中:选对节点承载方案,比优化节点合并逻辑更能实现性能飞跃。
七、总结
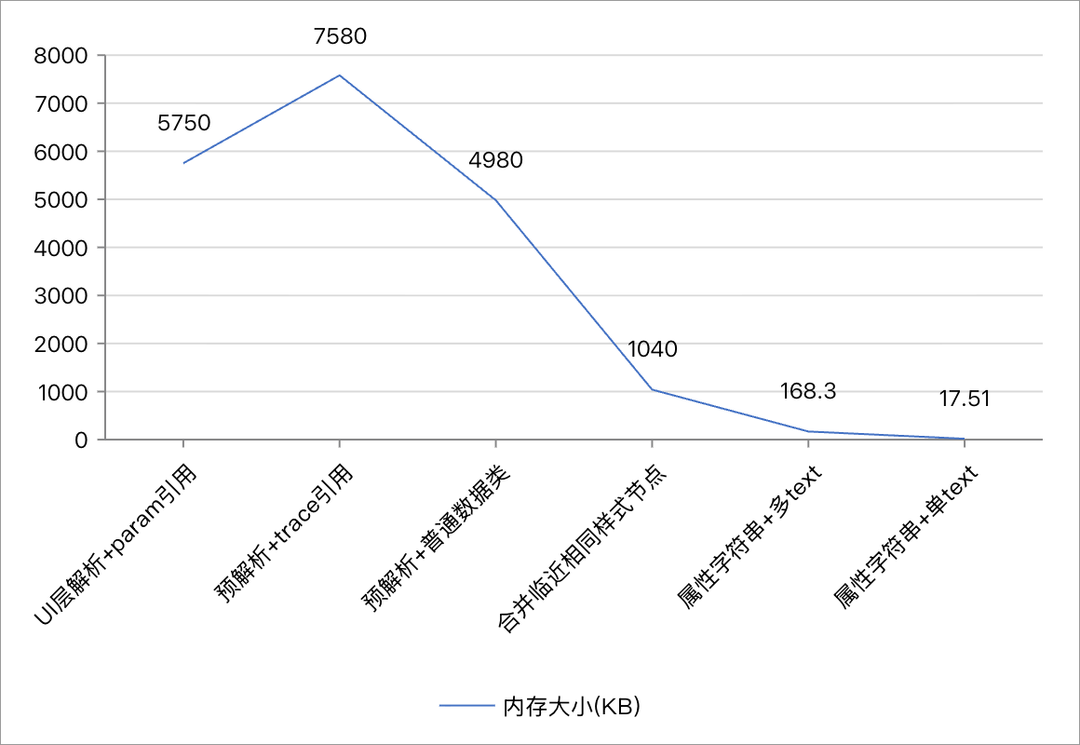
这里总结回顾一下各个版本的内存变化。
| 优化阶段 | 总内存 (KB) | updateFuncByElmtId 数量 | updateFuncByElmtId 内存 (KB) | use_refs 内存 (KB) |
|---|---|---|---|---|
| UI 层解析 + Param 直接引用 | 5750 | 7760 | 4470 | 192.48 |
| 预解析 + Trace 引用 | 7580 | 5635 | 3430 | 1 |
| 预解析 + 普通数据类 | 4980 | 5635 | 3430 | 1 |
| 预解析 + 合并相同 样式节点 | 1040 | 1325 | 868 | 1 |
| 预解析 + 属性字符串 (多 Text) | 168.3 | 106 | 106.15 | 1 |
| 预解析 + 属性字符串 (单 Text) | 17.51 | 8 | 4.25 | 1 |
1、各版本对比
1.1、初始版本:UI 层解析 + Param 直接引用(5750KB)
核心实现:在 UI 层直接解析代码块,通过forEach循环遍历文本片段时,直接引用@Param codeTheme配置样式。
● 关键问题:__use_refs__内存异常飙升至 192.48KB,其中codeTheme集合长度高达 4366。
● 底层原因:@Param装饰的对象在循环中被频繁引用,导致框架生成大量依赖追踪引用。
● 优化启示:UI 层应避免直接在forEach循环里操作配置类对象;可以通过数据预解析隔离依赖关系。
1.2、预解析 + Trace 引用(7580KB)
核心改进:将代码解析逻辑与 UI 层拆分,新增ObserverV2和Trace数据类跟踪数据变化,解决__use_refs__引用冗余问题。
● 矛盾点:__use_refs__内存降至 1KB,但总内存反而暴涨至 7580KB,涨幅达 32%。
● 深层原因:深入分析@ObserverV2源代码发现:
○ ObserverV2和Trace的响应式追踪机制会创建额外的类和依赖实例。
○ trace数量大于5个时。id_ref反向引用会新增大量 JSObject,导致内存失控。
● 优化启示:
○ 响应式装饰器并非万能,非高频更新场景应避免过度使用Trace,减少不必要的依赖追踪(没用上也会新增内存)。
○ ListItem中的Trace数量,尽量不要大于5个。
1.3、预解析 + 普通数据类(4980KB)
核心调整:保留 “解析与 UI 分离” 的架构,用普通interface替代ObserverV2和Trace,仅存储样式配置的纯数据结构。
● 优化效果:总内存降至 4980KB,低于初始版本,updateFuncByElmtId记录数稳定在 5635 条。
● 底层逻辑:普通数据类无响应式追踪开销,不会生成额外的依赖实例和闭包,仅保留必要的样式配置信息。
● 优化启示:纯展示类场景优先使用普通数据结构,仅在需要数据驱动更新时引入响应式装饰器。
1.4、预解析 + 合并临近相同样式节点(1040KB)
核心突破:深入分析 ViewV2 渲染流程,发现updateFuncByElmtId与 UI 节点一一对应,节点数量是内存占用的核心影响因子。
● 优化动作:遍历解析后的文本节点,合并相邻且样式完全一致的节点(如连续相同颜色、字体的 Span)。
● 关键数据:UI 节点数从 4949 降至 1025,updateFuncByElmtId记录数从 5635 减至 1325,内存直降 79%。
● 技术原理:减少节点数量即减少updateFuncByElmtId的绑定记录,能极大地降低内存。同时能降低布局计算和更新时的遍历开销。
1.5、预解析 + 属性字符串(单 Text)(17.51KB)
终极优化:放弃传统 Span 组件,采用鸿蒙属性字符串实现富文本样式,将整个代码块作为一个 Text 组件,用MutableStyledString承载全部内容和样式。
● 极致成果:总内存仅 17.51KB,接近纯 Text 组件的 14.1KB;updateFuncByElmtId仅 8 条,updateFuncByElmtId内存仅 4.25KB。
● 底层优势:**属性字符串复用单个原生节点,内存开销很低。**updateFuncByElmtId仅需维护一条记录,完全摆脱对细碎节点的依赖。
2、通用优化方法论:从基础到进阶
2.1、基础优化:节点精细化管理(性价比最高)
● 合并高频重复节点:列表、文本渲染等场景,优先合并样式 / 逻辑相同的相邻节点,减少无效节点拆分。
● 清理冗余节点:移除无文本、无独立样式、无更新依赖的空节点,避免嵌套布局中的重复包裹节点。
2.2、进阶优化:组件方案升维(突破性能天花板)
● 优先选择 “单节点多样式” 方案:在代码高亮等富文本场景,用属性字符串替代 Span 组件,从根源减少节点数量。
● 控制 Text 组件拆分粒度:长文本可采用 “整体一个 Text” 方案。需单独更新的片段按模块拆分,可以避免过度拆分导致的节点开销。
2.3、 响应式与数据结构优化(底层减负)
● 避免过度使用ObserverV2等数据驱动装饰注解:非数据驱动更新场景,用普通interface替代ObserverV2和Trace,减少闭包和依赖实例开销。
● 隔离 UI 层与配置依赖:通过预解析将配置类对象转换为纯数据结构,避免 UI 层直接引用@Param对象导致__use_refs__冗余。
● 警惕trace数量大于5:对ListItem中的ObserverV2类,trace数量大于5个时,会因为反向引用产生大量 JSObject。这会导致内存暴涨。